The primary use case for
dynamic SQL is the ability to write stored procedures that can support
optional parameters for queries in an efficient, maintainable manner.
Although it is quite easy to write static stored procedures that handle
optional query parameters, these are generally grossly inefficient or
highly unmaintainable—as a developer, you can take your pick.
Optional Parameters via Static T-SQL
Before presenting the
dynamic SQL solution to the optional parameter problem, a few
demonstrations are necessary to illustrate why static SQL is not the
right tool for the job. There are a few different methods of varying
complexity and effectiveness, but none deliver consistently.
As a baseline, consider the following query, which selects data from the HumanResources.Employee table in the AdventureWorks database:
SELECT
ContactId,
LoginId,
Title
FROM HumanResources.Employee
WHERE
EmployeeId = 1
AND NationalIdNumber = N'14417807'
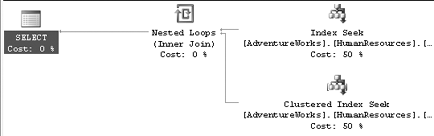
This query uses predicates to filter on both the EmployeeId and NationalIdNumber columns. Executing the query produces the execution plan shown in Figure 1,
which has an estimated cost of 0.0032831, and which requires two
logical reads. This plan involves a seek of the table's clustered index,
which uses the EmployeeId column as its key.

Since the query uses the clustered index, it does not need to do a lookup to get any additional data. Furthermore, since EmployeeId is the primary key for the table, the NationalIdNumber predicate is not used when physically identifying the row. Therefore, the following query, which uses only the EmployeeId predicate, produces the exact same query plan with the same cost and same number of reads:
SELECT
ContactId,
LoginId,
Title
FROM HumanResources.Employee
WHERE
EmployeeId = 1
Another form of this query involves removing EmployeeId and querying based only on NationalIdNumber:
SELECT
ContactId,
LoginId,
Title
FROM HumanResources.Employee
WHERE
NationalIdNumber = N'14417807'
This query results in a very
different plan from the other two, due to the fact that a different
index must be used to satisfy the query. Figure 2 shows the resultant plan, which involves a seek on a nonclustered index on the NationalIdNumber column, followed by a lookup to get the additional rows for the SELECT list. This plan has an estimated cost of 0.0065704, and does four logical reads.
The final form of the base query has no predicates at all:
SELECT
ContactId,
LoginId,
Title
FROM HumanResources.Employee
As shown in Figure 3,
the query plan is a simple clustered index scan, with an estimated cost
of 0.0080454, and nine logical reads. Since all of the rows need to be
returned and no index covers every column required, a clustered index
scan is the most efficient way to satisfy this query.

These baseline numbers will
be used to compare the relative performance of various methods of
creating a dynamic stored procedure that returns the same columns, but
which optionally enables one or both predicates. To begin with, the
query can be wrapped in a stored procedure:
CREATE PROCEDURE GetEmployeeData
@EmployeeId INT = NULL,
@NationalIdNumber NVARCHAR(15) = NULL
AS
BEGIN
SET NOCOUNT ON
SELECT
ContactId,
LoginId,
Title
FROM HumanResources.Employee
WHERE
EmployeeId = @EmployeeId
AND NationalIdNumber = @NationalIdNumber
END
This stored procedure uses the parameters @EmployeeId and @NationalIdNumber to support the predicates. Both of these parameters are optional, with NULL
default values. However, this stored procedure does not really support
the parameters optionally; not passing one of the parameters will mean
that no rows will be returned by the stored procedure at all, since any
comparison with NULL in a predicate will not result in a true answer.
As a first
shot at making this stored procedure optionally enable the predicates, a
developer might try control of flow and rewrite the procedure as
follows:
CREATE PROCEDURE GetEmployeeData
@EmployeeId INT = NULL,
@NationalIdNumber NVARCHAR(15) = NULL
AS
BEGIN
SET NOCOUNT ON
IF (@EmployeeId IS NOT NULL
AND @NationalIdNumber IS NOT NULL)
BEGIN
SELECT
ContactId,
LoginId,
Title
FROM HumanResources.Employee
WHERE
EmployeeId = @EmployeeId
AND NationalIdNumber = @NationalIdNumber
END
ELSE IF (@EmployeeId IS NOT NULL)
BEGIN
SELECT
ContactId,
LoginId,
Title
FROM HumanResources.Employee
WHERE
EmployeeId = @EmployeeId
END
ELSE IF (@NationalIdNumber IS NOT NULL)
BEGIN
SELECT
ContactId,
LoginId,
Title
FROM HumanResources.Employee
WHERE
NationalIdNumber = @NationalIdNumber
END
ELSE
BEGIN
SELECT
ContactId,
LoginId,
Title
FROM HumanResources.Employee
END
END
Although executing this
stored procedure produces the exact same query plans—and, therefore, the
exact same performance—as the test batches, it has an unfortunate
problem. Namely, taking this approach turns what was a very simple
10-line stored procedure into a 42-line monster. Consider that when
adding a column to the SELECT list for
this procedure, a change would have to be made in four places. Now
consider what would happen if a third predicate were needed—the number
of cases would jump from four to eight, meaning that any change such as
adding or removing a column would have to be made in eight places. Now
consider 10 or 20 predicates, and it's clear that this method has no
place in the SQL Server developer's toolbox. It is simply not a
manageable solution.
The next most common
technique is one that has appeared in articles on several SQL Server web
sites over the past few years. As a result, a lot of code has been
written against it by developers who don't seem to realize that they're
creating a performance time bomb. This technique takes advantage of the COALESCE function, as shown in the following rewritten version of the stored procedure:
CREATE PROCEDURE GetEmployeeData
@EmployeeId INT = NULL,
@NationalIdNumber NVARCHAR(15) = NULL
AS
BEGIN
SET NOCOUNT ON
SELECT
ContactId,
LoginId,
Title
FROM HumanResources.Employee
WHERE
EmployeeId = COALESCE(@EmployeeId, EmployeeId)
AND NationalIdNumber = COALESCE(@NationalIdNumber, NationalIdNumber)
END
This version of the stored procedure looks great and is easy to understand. The COALESCE function returns the first non-NULL value passed into its parameter list. So if either of the arguments to the stored procedure are NULL, the COALESCE will "pass through," comparing the value of the column to itself—and at least in theory, that seems like it should be a no-op.
Unfortunately, because the COALESCE
function uses a column from the table as an input, it cannot be
evaluated deterministically before execution of the query. The result is
that the function is evaluated once for every row of the table,
resulting in a table scan. This means consistent results, but probably
not in a good way; all four combinations of parameters result in the
same query plan, a clustered index scan with an estimated cost of
0.0080454 and nine logical reads. This is over four times the I/O for
the queries involving the EmployeeId column—quite a performance drain.
Similar to the version that uses COALESCE is a version that uses OR to conditionally set the parameter only if the argument is not NULL:
CREATE PROCEDURE GetEmployeeData
@EmployeeId INT = NULL,
@NationalIdNumber NVARCHAR(15) = NULL
AS
BEGIN
SET NOCOUNT ON
SELECT
ContactId,
LoginId,
Title
FROM HumanResources.Employee
WHERE
(@EmployeeId IS NULL
OR EmployeeId = @EmployeeId)
AND (@NationalIdNumber IS NULL
OR @NationalIdNumber = NationalIdNumber)
END
This version, while similar in idea to the version that uses COALESCE,
has some interesting performance traits. Depending on which parameters
you use the first time you call it, you'll see vastly different results.
If you're lucky enough to call it the first time with no arguments, the
result will be an index scan, producing nine logical reads—and the same
number of reads will result for any combination of parameters passed in
thereafter. If, however, you first call the stored procedure using only
the @EmployeeId parameter, the
resultant plan will use only four logical reads—until you happen to call
the procedure with no arguments, and it produces a massive 582 reads.
Given the surprisingly huge
jump in I/O that the bad plan can produce, as well as the unpredictable
nature of what performance characteristics you'll end up with, this is
undoubtedly the worst possible choice.
The final method that can
be used is a bit more creative, and also can result in somewhat-better
results. The following version of the stored procedure shows how it is
implemented:
CREATE PROCEDURE GetEmployeeData
@EmployeeId INT = NULL,
@NationalIdNumber NVARCHAR(15) = NULL
AS
BEGIN
SET NOCOUNT ON
SELECT
ContactId,
LoginId,
Title
FROM HumanResources.Employee
WHERE
EmployeeId BETWEEN
COALESCE(@EmployeeId, −2147483648)
AND COALESCE(@EmployeeId, 2147483647)
AND NationalIdNumber LIKE COALESCE(@NationalIdNumber, N'%')
END
If you're a bit
confused by the logic of this stored procedure, you're now familiar with
the first reason that I don't recommend this technique: it's relatively
unmaintainable if you don't understand exactly how it works. Using it
almost certainly guarantees that you will produce stored procedures that
will stump others who attempt to maintain them in the future. And while
that might be good for job security, using it for that purpose is
probably not a virtuous goal.
This stored procedure operates by using COALESCE to cancel out NULL arguments by substituting in minimum and maximum conditions for the integer predicate (EmployeeId) and a LIKE expression that will match anything for the string predicate (NationalIdNumber).
If @EmployeeId is NULL, the EmployeeId predicate effectively becomes EmployeeId BETWEEN −2147483648 AND 2147483647—in other words, all possible integers. If @EmployeeId is not NULL, the predicate becomes EmployeeId BETWEEN @EmployeeId AND @EmployeeId. This is equivalent with EmployeeId=@EmployeeId.
The same basic logic is true for the NationalIdNumber predicate, although because it's a string instead of an integer, LIKE is used instead of BETWEEN. If @NationalIdNumber is NULL, the predicate becomes NationalIdNumber LIKE N'%'. This will match any string in the NationalIdNumber column. On the other hand, if @NationalIdNumber is not NULL, the predicate becomes NationalIdNumber LIKE @NationalIdNumber, which is equivalent with NationalIdNumber=@NationalIdNumber—assuming that @NationalIdNumber contains no string expressions. This predicate can also be written using BETWEEN to avoid the string expression issue (for instance: BETWEEN N'' AND REPLICATE(NCHAR(1000), 15)). However, that method is both more difficult to read than the LIKE expression and fraught with potential problems due to collation issues (which is why I only went up to NCHAR(1000) instead of NCHAR(65535) in the example).
The real question, of
course, is one of performance. Unfortunately, this stored procedure
manages to confuse the query optimizer, resulting in the same plan being
generated for every invocation. The plan, in every case, involves a
clustered index seek on the table, with an estimated cost of 0.0048592,
as shown in Figure 4.
Unfortunately, this estimate turns out to be highly inconsistent, as
the number of actual logical reads varies widely based on the arguments
passed to the procedure.

If both arguments are passed or @EmployeeId is passed but @NationalIdNumber
is not, the number of logical reads is three. While this is much better
than the nine logical reads required by the previous version of the
stored procedure, it's still 50% more I/O than the two logical reads
required by the baseline in both of these cases. This estimated plan
really breaks down when passing only @NationalIdNumber, since there is no way to efficiently satisfy a query on the NationalIdNumber column using the clustered index. In both that case and when passing no arguments, nine logical reads are reported. For the NationalIdNumber predicate this is quite a failure, as the stored procedure does over twice as much work for the same results as the baseline.