Dynamic T-SQL vs. Ad Hoc T-SQL
Before I begin a serious
discussion about how dynamic SQL should be used, it's first important to
establish a bit of terminology. Two terms that are often intermingled
in the database world with regard to SQL are dynamic and ad hoc.
I consider any batch of SQL generated dynamically by an application
layer and sent to SQL Server for execution to be ad hoc SQL. Dynamic
SQL, on the other hand, I define as a batch of SQL that is generated within T-SQL and executed using the EXECUTE statement or, preferably, via the sp_executesql system stored procedure .
The Stored Procedure vs. Ad Hoc SQL Debate
A seemingly never-ending
battle in online database forums concerns the question of whether
database application development should involve the use of stored
procedures or not. This question can become quite complex, with
proponents of rapid software development methodologies such as
Test-Driven Development (TDD) claiming that stored procedures slow down
their process, and fans of Object-Relational Mapping (ORM) technologies
making claims about the benefits of those technologies over stored
procedures. It does not help that many of the combatants in these
battles happen to have a vested interest in ORM; some of the most heated
debates in recent memory were started by inflammatory claims made by
vendors of ORM tools.
I highly recommend that
you search the Web to find these debates and reach your own conclusions.
Personally, I heavily favor the use of stored procedures, for several
reasons that I will briefly discuss here.
First and foremost,
stored procedures create an abstraction layer between the database and
the application, hiding details about both the schema and, sometimes,
the data. The encapsulation of data logic within stored procedures
greatly decreases coupling between the database and the application,
meaning that maintenance of or modification to the database will not
necessitate changing the application accordingly. Reducing these
dependencies and thinking of the database as a data API rather than a
simple application persistence layer translates into a much more
flexible application development process. Often, this can permit the
database and application layers to be developed in parallel rather than
in sequence, thereby allowing for greater scale-out of human resources
on a given project.
If stored procedures are
properly defined, with well-documented and consistent outputs, testing
is not at all hindered—unit tests can be easily created. Furthermore, support for more advanced testing
methodologies also becomes easier, not more difficult, thanks to stored
procedures. For instance, consider use of mock objects,
façade methods that TDD practitioners create which return specific
known values. These are then substituted for real methods in testing
scenarios such that testing any given method does not test any methods
that it calls (any calls made from within the method being tested will
actually be a call to a mock version of the method). This technique is
actually much easier to implement for testing of data access when stored
procedures are used, as mock stored procedures can easily be created
and swapped in and out without disrupting or recompiling the application
code being tested.
Another important issue is
security. Ad hoc SQL (as well as dynamic SQL) presents various security
challenges, including opening possible attack vectors and making data
access security much more difficult to enforce declaratively, rather
than programmatically. This means that by using ad hoc SQL your
application may be more vulnerable to being hacked, and you may not be
able to rely on SQL Server to secure access to data. The end result is
that a greater degree of testing will be required in order to ensure
that security holes are properly patched and that users—both authorized
and not—are unable to access data they're not supposed to see.
Finally, I will
address the hottest issue that online debates always seem to gravitate
toward. Of course, this is none other than the question of performance.
Proponents of ad hoc SQL make the valid claim that, thanks to better
support for query plan caching in SQL Server 2000 and 2005, stored
procedures no longer have much of a performance benefit. (Please note,
this is only true if ad hoc or dynamic SQL is properly used in either
case!
In the end, the
stored procedure vs. ad hoc SQL question is really one of purpose. Many
in the ORM community feel that the database should be used as nothing
more than a very simple object persistence layer, and would probably be
perfectly happy with a database that only had a single table with only
two columns: a GUID to identify an object's ID and an XML column for the
serialized object graph.
In
my eyes, a database is much more than just a collection of data. It is
also an enforcer of data rules, a protector of data integrity, and a
central data resource that can be shared among multiple applications.
For these reasons, I firmly believe that a decoupled, stored
procedure-based design is the only way to go.
Why Go Dynamic?
Dynamic SQL can help create more flexible
data access layers, thereby helping to enable more flexible
applications, which makes for happier users. This is a righteous goal,
but the fact is that dynamic SQL is just one means by which to attain
the desired end result. It is quite possible—in fact, often
preferable—to do dynamic sorting and filtering directly on the client in
many desktop applications, or in a business layer, if one exists to
support either a web-based or client-server-style desktop application.
It is also possible to not go dynamic at all, and support static stored
procedures that supply optional parameters—but that's not generally
recommended.
Before
committing to any database-based solution, determine whether it is
really the correct course of action. Keep in mind the questions of
performance, maintainability, and most important, scalability. Database
resources are often the most taxed of any used by a given application,
and dynamic sorting and filtering of data can potentially mean a lot
more load put on the database. Remember that scaling the database can
often be much more expensive than scaling other layers of an
application.
For example, consider
the question of sorting data. In order for the database to sort data,
the data must be queried. This means that it must be read from disk or
memory, thereby using I/O and CPU time, filtered appropriately, and
finally sorted and returned to the caller. Every time the data needs to
be resorted a different way, it must be reread or sorted in memory and
refiltered by the database engine. This can add up to quite a bit of
load if there are hundreds or thousands of users all trying to sort data
in different ways, and all sharing resources on the same database
server.
Due to this issue, if the
same data is resorted again and again (for instance, by a user who wants
to see various high or low data points), it often makes sense to do the
work in a disconnected cache. A desktop application that uses a
client-side data grid, for example, can load the data only once, and
then sort and resort it using the client computer's resources rather
than the database server's resources. This can take a tremendous amount
of strain off of the database server, meaning that it can use its
resources for other data-intensive operations.
Once you've exhausted all other resources, only then
should you look at the database as a solution for dynamic operations.
In the database layer, the question of using dynamic SQL instead of
static SQL comes down to issues of both maintainability and performance.
The fact is, dynamic SQL can be made to perform much better than simple
static SQL for many dynamic cases, but more complex (and difficult to
maintain) static SQL will generally outperform maintainable dynamic SQL
solutions. For the best balance of maintenance vs. performance, I always
favor the dynamic SQL solution.
Compilation and Parameterization
Any discussion of
dynamic SQL and performance is not possible to fully comprehend without a
basic background understanding of how SQL Server processes queries and
caches their plans. To that end, I will provide a brief discussion here,
with some examples to help you get started in investigating these
behaviors within SQL Server.
Every query executed by
SQL Server goes through a compilation phase before actually being
executed by the query processor. This compilation produces what is known
as a query plan,
which tells the query processor how to physically access the tables and
indexes in the database in order to satisfy the query. However, query
compilation can be expensive for certain queries, and when the same
queries or types of queries are executed over and over, there generally
is no reason to compile them each time. In order to save on the cost of
compilation, SQL Server caches query plans in a memory pool called the query plan cache.
The query plan cache
uses a simple hash lookup based on the exact text of the query in order
to find a previously compiled plan. If the exact query has already been
compiled, there is no reason to recompile it, and SQL Server skips
directly to the execution phase in order to get the results for the
caller. If a compiled version of the query is not found, the first step
taken is parsing of the query. SQL Server determines which operations
are being conducted in the SQL, does validation of syntax, and produces a
parse tree, which is a structure that contains information about the query in a normalized form.
The parse tree is further validated and eventually compiled into a
query plan, which is placed into the query plan cache for future
invocations of the query.
The effect of the
query plan cache on execution time can be seen even with simple queries.
To see the amount of time spent in the parsing and compilation phase,
turn on SQL Server's SET STATISTICS TIME
option, which causes SQL Server to output informational messages about
time spent in parsing/compilation and execution. For example, consider
the following T-SQL, which turns on time statistics, and then queries
the HumanResources.Employee table, which can be found in the AdventureWorks database:
SET STATISTICS TIME ON
GO
SELECT *
FROM HumanResources.Employee
WHERE EmployeeId IN (1, 2)
GO
Executing this query in
SQL Server Management Studio on my system produces the following output
messages the first time the query is run:
SQL Server parse and compile time:
CPU time = 0 ms, elapsed time = 5 ms.
(2 row(s) affected)
SQL Server Execution Times:
CPU time = 0 ms, elapsed time = 1 ms.
This query took 5
milliseconds to parse and compile. But subsequent runs produce the
following output, indicating that the cached plan is being used:
SQL Server parse and compile time:
CPU time = 0 ms, elapsed time = 1 ms.
(2 row(s) affected)
SQL Server Execution Times:
CPU time = 0 ms, elapsed time = 1 ms.
Thanks to the cached
plan, each subsequent invocation of the query takes 4 milliseconds less
than the first invocation—not bad, when you consider that the actual
execution time is less than 1 millisecond (the lowest elapsed time
reported by time statistics).
NOTE
In order to simplify the output a bit, I ran SET STATISTICS TIME OFF between the two runs shown here. Otherwise, you would see additional times reported for the SET STATISTICS TIME ON
statement. It's also important to note that during testing it is
possible to clear out the query plan cache, and I did that on my end as
well in order to show you clean output. To clear out the cache, use the DBCC FREEPROCCACHE
command. Keep in mind that this command clears out the cache for the
entire instance of SQL Server—doing this is not generally recommended in
production environments. Another option is DBCC FLUSHPROCINDB,
which has a single parameter, a database ID for which to clear the
procedure cache. Since it only clears the cache for a single database,
it may be a better alternative to DBCC FREEPROCCACHE.
However, the command is undocumented, which means that it's not
officially supported by Microsoft. Use it at your own risk, preferably
only in development environments.
Auto-Parameterization
An important part of the
parsing process that enables the query plan cache to be more efficient
in some cases involves determination of which parts of the query qualify
as parameters. If SQL Server determines that one or more literals used
in the query are parameters that may be changed for future invocations
of a similar version of the query, it can auto-parameterize the query. To understand what this means, let's first take a glance into the query plan cache, via the sys.dm_exec_cached_plans dynamic management view and the sys.dm_exec_sql_text
function. The following query finds all cached queries that contain the
string "HumanResources", except those that contain the name of the view
itself—this second predicate is necessary so that the plan for the
query to see the query plans is not returned.
SELECT
ecp.objtype,
p.Text
FROM sys.dm_exec_cached_plans AS ecp
CROSS APPLY
(
SELECT *
FROM sys.dm_exec_sql_text(ecp.plan_handle)
) p
WHERE
p.Text LIKE '%HumanResources%'
AND p.Text NOT LIKE '%sys.dm_exec_cached_plans%'
Querying the view after executing the previous query against HumanResources.Employee results in the output shown in Figure 1. The important things to note here are that the objtype column indicates that the query is being treated as ad hoc, and that the Text
column shows the exact text of the executed query. Queries that cannot
be auto-parameterized are classified by the query engine as "ad hoc"
(obviously, this is a slightly different definition from the one I use).

The previous example
query was used to keep things simple, precisely because it could not be
auto-parameterized. The following query, on the other hand, can be
auto-parameterized:
SELECT *
FROM HumanResources.Employee
WHERE EmployeeId = 1
Clearing the execution plan cache, running this query, and finally querying the view again results in the output shown in Figure 2.
In this case, two plans have been generated: an ad hoc plan for the
query's exact text and a prepared plan for the auto-parameterized
version of the query. Looking at the text of the latter plan, notice
that the query has been normalized (the object names are
bracket-delimited, carriage returns and other extraneous white space
have been removed, and so on) and that a parameter has been derived from
the text of the query.

The benefit of
this auto-parameterization is that subsequent queries submitted to SQL
Server that can be auto-parameterized to the same normalized form may be
able to make use of the prepared query plan, thereby avoiding
compilation overhead.
NOTE
The
auto-parameterization examples shown here were done using the
AdventureWorks database with its default options set, including the
"simple parameterization" option, which tells the query engine not to
work too hard to auto-parameterize queries. SQL Server 2005 includes an
option to turn on a more powerful form of auto-parameterization, called
"forced parameterization." This option makes SQL Server work much harder
to auto-parameterize queries, which means greater query compilation
cost in some cases. This can be very beneficial to applications that use
a lot of nonparameterized ad hoc queries, but may cause performance
degradation in other cases.
Application-Level Parameterization
Auto-parameterization is
not the only way that a query can be parameterized. Other forms of
parameterization are possible at the application level for ad hoc SQL,
or within T-SQL when working with dynamic SQL in a stored procedure.
Every query framework that
can communicate with SQL Server supports the idea of Remote Procedure
Call (RPC) invocation of queries. In the case of an RPC call, parameters
are bound and strongly typed, rather than encoded as strings and passed
along with the rest of the query text. Parameterizing queries in this
way has one key advantage from a performance standpoint: the application
tells SQL Server what the parameters are; SQL Server does not need to
(and will not) try to find them itself.
To illustrate how this
works, I will show you an example using the SQLQueryStress tool.
SQLQueryStress uses parameterized queries to support its parameter
substitution mode.
To see the
effect of parameterization, load the tool and configure the Database
options to connect to an instance of SQL Server and use AdventureWorks
as the default database. Next, enter the following query into the Query
textbox:
SELECT *
FROM HumanResources.Employee
WHERE EmployeeId IN (@EmpId1, @EmpId2)
This query is the same as
the query shown in the previous section that SQL Server was unable to
auto-parameterize. However, in this case, the literal employee IDs have
been replaced with the variables @EmpId1 and @EmpId2.
Once the query is in
place, click the Parameter Substitution button and put the following
query into the Parameter Query textbox:
SELECT 1 AS EmpId1, 2 AS EmpId2
This query returns one row,
containing the values 1 and 2, which will be substituted into the outer
query as parameters for the RPC call. Once this query is in the
textbox, click the Get Columns button and map the EmpId1 column to @EmpId1 and the EmpId2 column to @EmpId2. When you are finished, your column mappings should look like what's shown in Figure 3.
Once done mapping, click OK, and then click GO to run the query (don't
bother setting iterations or threads above 1—this run is not a load
test).

Once you have run the query, go back into SQL Server Management Studio and query the sys.dm_exec_cached_plans view using the query from the previous section. The result should be the same as that shown in Figure 4.
Just like with auto-parameterized queries, the plan is prepared, and
the text is prefixed with the parameters. However, notice that the text
of the query is not normalized. The object name is not
bracket-delimited, and although it is not apparent in this screenshot,
white space has not been removed. This fact is extremely important! If
you were to run the same query, but with slightly different formatting,
you would get a second plan—so when working with parameterized queries,
make sure that the application generating the query produces the exact
same formatting every time. Otherwise, you will end up wasting both the
CPU cycles required for needless compilation and memory for caching the
additional plans.
NOTE
White space is not
the only type of formatting that can make a difference in terms of plan
reuse. The cache lookup mechanism is nothing more than a simple hash on
the query text and is case sensitive. So the exact same query submitted
twice with different capitalization will be seen by the cache as
different queries—even on a case-insensitive server. It's always a good
idea when working with SQL Server to try to be consistent with your use
of capitalization and formatting. Not only does it make your code more
readable, but it may wind up improving performance!

Performance Implications of Parameterization and Caching
Now that all of the
background information has been covered, the burning question can be
answered: why should you care, and what does any of this have to do with
dynamic SQL? The answer, of course, is that this has everything to do
with dynamic SQL, if you care about performance (and other issues, but
we'll get to those shortly).
If you're not still in
SQLQueryStress from the previous section, load the tool back up and get
it to the same state that it was in at the end of the section. Now,
click the Parameter Substitution button, and enter the following query
into the Parameter Query textbox:
SELECT Number, Number + 1 AS NumberPlus1
FROM master..spt_values
WHERE Type = 'P'
This query uses the master..spt_values table, which happens to contain every number from 0 to 2047 in a column called Number, keyed off of the Type of P.
(Whatever that means—this table is undocumented and appears to be used
only by one system stored procedure, also undocumented, called sp_MSobjectprivs. But it certainly does come in handy when you need some numbers, stat.)
In the Parameter Mappings section, map the Number column to @EmpId1, and NumberPlus1 to @EmpId2.
When you're done, click OK and set the Number of Iterations to 2048 in
order to go through every number returned by the substitution query.
Once you've finished configuring, click GO to start the run. Figure 5 shows the output from the run on my system.
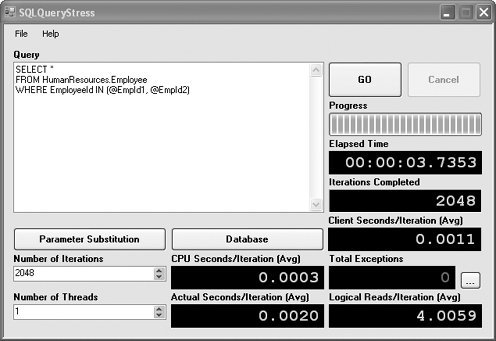
Once again, return to SQL Server Management Studio and query the sys.dm_exec_cached_plans
view, and you will see that the results have not changed. There is only
one plan in the cache for this form of the query, even though it has
just been run 2,048 times with different parameter values. This
indicates that parameterization is working, and the server does not need
to do extra work to compile the query every time a slightly different
form of it is issued.
Now that a positive baseline has been established, let's investigate what happens when queries are not properly parameterized. Back in SQLQueryStress, enter the following query into the Query textbox:
DECLARE @sql VARCHAR(MAX)
SET @sql =
'SELECT *
FROM HumanResources.Employee
WHERE EmployeeId IN (' +
CONVERT(VARCHAR, @EmpId1) + ', ' +
CONVERT(VARCHAR, @EmpId2) + ')'
EXEC(@sql)
Since
SQLQueryStress uses parameterized queries for its parameter substitution
mode, a bit of tweaking is necessary to get it to load test
nonparameterized queries with substitution. In this case, a dynamic SQL
string is built using the input parameters and the resultant query
executed using the EXECUTE statement. Once you're
ready, click GO to start the run. The results of the run from my system
are shown in Figure 6.
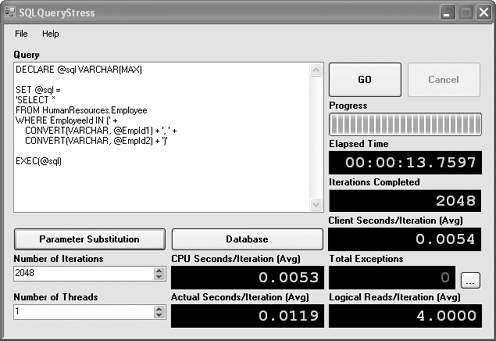
The end result shown
here should be enough to make you a believer in the power of
parameterization. But just in case you're still not sure, jump back into
SQL Server Management Studio one final time and query the sys.dm_exec_cached_plans view for a nice surprise. The abbreviated results of the query as run on my system are shown in Figure 7.
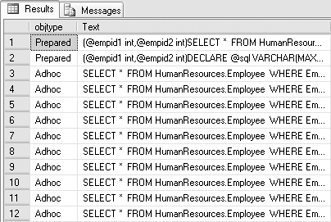
Running 2,048
nonparameterized ad hoc queries with different parameters resulted in
2,048 additional cached plans. That means not only the slowdown apparent
in the average seconds per iteration counters (resulting from the
additional compilation), but also that quite a bit of RAM is now wasted
in the query plan cache. In SQL Server 2005, queries are aged out of the
plan cache on a least-recently-used basis, and depending on the
server's workload it can take quite a bit of time for unused plans to be
removed.
In
a large production environment, not using parameterized queries can
result in gigabytes of RAM being wasted caching query plans that will
never be used again. This is obviously not a good thing! So please—for
the sake of all of that RAM—learn to use your connection library's
parameterized query functionality and avoid falling into this trap.