3. Indexed views
A traditional, nonindexed view provides a filter
over one or more tables. Used for various purposes, views are an
excellent mechanism for abstracting table join complexity and securing
data. Indexed views, introduced in SQL Server 2000, materialize the
results of the view. Think of an indexed view as another table with its
own data, the difference being the data is sourced from one or more
other tables. Indexed views are sometimes referred to as virtual tables.
To illustrate the power of indexed views, where sales
data is summarized by product and date. The original query, run against
the base tables, is shown in listing 2.
Example 2. Sorted and grouped sales orders
-- Return orders grouped by date and product name
SELECT
o.OrderDate
, p.Name as productName
, sum(UnitPrice * OrderQty * (1.00-UnitPriceDiscount)) as revenue
, count_big(*) as salesQty
FROM Sales.SalesOrderDetail as od
INNER JOIN Sales.SalesOrderHeader as o
ON od.SalesOrderID = o.SalesOrderID
INNER JOIN Production.Product as p
ON od.ProductID = p.ProductID
WHERE o.OrderDate between '1 July 2001' and '31 July 2001'
GROUP BY o.OrderDate, p.Name
ORDER BY o.OrderDate, p.Name
|
What we're doing here is selecting the total
sales (dollar total and count) for sales from July 2001, grouped by date
and product. The I/O statistics for this query are as follows:
Table Worktable:
Scan count 0, logical reads 0, physical reads 0, read-ahead reads 0
Table SalesOrderDetail:
Scan count 184, logical reads 861, physical reads 1, read-ahead reads 8
Table SalesOrderHeader:
Scan count 1, logical reads 703, physical reads 1, read-ahead reads 699
Table Product:
Scan count 1, logical reads 5, physical reads 1, read-ahead reads 0
The AdventureWorks database is quite small, and
as a result, the query completes in only a few seconds. On a much
larger, real-world database, the query would take substantially longer,
with a corresponding user impact. Consider the execution plan for this
query, as shown in figure 8.
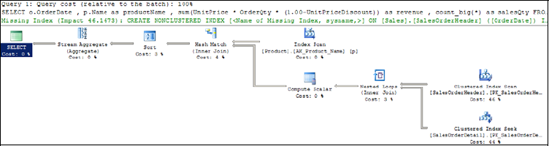
The join, grouping, and sorting logic in this
query are all contributing factors to its complexity and disk I/O usage.
If this query was run once a day and after hours, then perhaps it
wouldn't be much of a problem, but consider the user impact if this
query was run by many users throughout the day.
Using indexed views, we can materialize the results of this query, as shown in listing 3.
Example 3. Creating an indexed view
-- Create an indexed view
CREATE VIEW Sales.OrdersView
WITH SCHEMABINDING
AS
SELECT
o.OrderDate
, p.Name as productName
, sum(UnitPrice * OrderQty * (1.00-UnitPriceDiscount)) as revenue
, count_big(*) as salesQty
FROM Sales.SalesOrderDetail as od
INNER JOIN Sales.SalesOrderHeader as o
ON od.SalesOrderID = o.SalesOrderID
INNER JOIN Production.Product as p
ON od.ProductID = p.ProductID
GROUP BY o.OrderDate, p.Name
GO
--Create an index on the view
CREATE UNIQUE CLUSTERED INDEX ixv_productSales
ON Sales.OrdersView (OrderDate, productName);
GO
|
Notice the WITH SCHEMABINDING used when
creating the view. This essentially ties the view to the table
definition, preventing structural table changes while the view exists.
Further, creating the unique clustered index in the second half of the
script is what materializes the results of the view to disk. Once
materialized, the same query that we ran before can be run again, without needing to reference the indexed view. The difference can be seen in the I/O statistics and dramatically simpler query execution plan, as shown in figure 9.
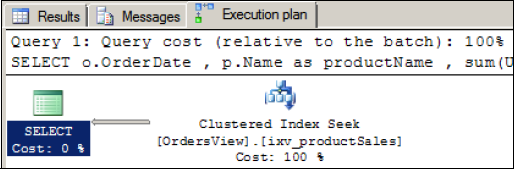
Essentially, what we've done in creating the indexed view is store, or materialize,
the results such that the base tables no longer need to be queried to
return the results, thereby avoiding the (expensive) aggregation process
to calculate revenue and sales volume. The I/O statistics for the query
using the indexed view are as follows:
Table OrdersView:
Scan count 1, logical reads 5, physical reads 1, read-ahead reads 2
That's a total of 5 logical reads, compared to
1500-plus before the indexed view was created. You can imagine the
accumulated positive performance impact of the indexed view if the query
was run repeatedly throughout the day.
Once an indexed view is materialized with the
unique clustered index, additional nonclustered indexes can be created
on it; however, the same performance impact and index maintenance
considerations apply as per a standard table.
Used correctly, indexed views are incredibly
powerful, but there are several downsides and considerations. The
primary one is the overhead in maintaining the view; that is, every time
a record in one of the view's source tables is modified, the
corresponding updates are required in the indexed view, including
re-aggregating results if appropriate. The maintenance overhead for
updates on the base tables may outweigh the read performance benefits;
thus, indexed views are best used on tables with infrequent updates.
The major
ones are as follows:
Schema binding on the base tables prevents any schema changes to the underlying tables while the indexed view exists.
The
index that materializes the view, that is, the initial clustered index,
must be unique; hence, there must be a unique column, or combination of
columns, in the view.
The indexed view cannot include n/text or image columns.
The indexed view that we created in the previous
example for sales data grouped by product and date was one of many
possible implementations. A simpler example of an indexed view follows:
-- Create an indexed view
CREATE VIEW Person.AustralianCustomers
WITH SCHEMABINDING
AS
SELECT CustomerID, LastName, FirstName, EmailAddress
FROM Person.Customer
WHERE CountryCode = 'AU'
go
CREATE UNIQUE CLUSTERED INDEX ixv_AustralianCustomers
ON Person.AustralianCustomers(CustomerID);
GO
Indexed views vs. filtered indexes
We can use both filtered indexes and indexed
views to achieve fast lookups for subsets of data within a table. The
method chosen is based in part on the constraints and limitations of
each method. We've covered some of the indexed view restrictions (schema
binding, no n/text or image columns, and so forth). When it comes to
filtered indexes, the major restriction is the fact that, like full
table indexes, they can be defined on only a single table. In contrast,
as you saw in our example with sales data, an indexed view can be
created across many tables joined together.
Additional
restrictions apply to the predicates
for a filtered index. In our earlier example, we created filtered
indexes with simple conditions such as where CountryCode = 'AU'. More
complex predicates such as string comparisons using the LIKE operator
are not permitted in filtered indexes, nor are computed columns.
Data type conversion
is not permitted on the
left-hand side of a filtered index predicate, for example, a table
containing a varbinary(4) column named col1, with a filter predicate
such as where col1 = 10. In this case, the filtered index would fail
because col1 requires an implicit binary-to-integer conversion.
In summary, filtered indexes are best used
against single tables with simple predicates where the row volume of the
index is a small percentage of the total table row count. In contrast,
indexed views are a powerful solution for multi-table join scenarios
with aggregate calculations and more complex predicates on tables that
are infrequently updated. Perhaps the major determining factor is the
edition of SQL Server used. While indexed views can be created in any
edition of SQL Server, they'll be automatically considered for use only
in the Enterprise edition. In other editions, they need to be explicitly
referenced with the NOEXPAND query hint.
With these index design
points in mind, let's now look at processes and techniques for analyzing
indexes to determine their usage and subsequent maintenance
requirements.