2. Improving nonclustered index efficiency
The
accumulated cost of random I/O involved in key/RID lookups often leads
to nonclustered indexes being ignored in favor of sequential I/O with
clustered index scans. To illustrate this and explore options for
avoiding the key lookup process, let's walk through a number of examples
using the Person. Contact table in the sample AdventureWorks database.
In demonstrating how SQL Server uses different indexes for different
queries, we'll view the graphical execution plans, which use different
icons, as shown in figure 1, to represent different actions (lookups, scans, seeks, and so forth).
|
Several important terms are used when discussing index usage. An index seek
is used when the query optimizer chooses to navigate through the levels
of a clustered or nonclustered index B-tree to quickly reach the
appropriate leaf level pages. In contrast, an index scan, as the name suggests, scans the leaf level, left to right, one page at a time.
|

The Person.Contact table, as defined below
(abbreviated table definition), contains approximately 20,000 rows. For
the purposes of this test, we'll create a nonunique, nonclustered index
on the LastName column:
-- Create a contact table with a nonclustered index on LastName
CREATE TABLE [Person].[Contact](
[ContactID] [int] IDENTITY(1,1) PRIMARY KEY CLUSTERED
, [Title] [nvarchar](8) NULL
, [FirstName] [dbo].[Name] NOT NULL
, [LastName] [dbo].[Name] NOT NULL
, [EmailAddress] [nvarchar](50) NULL
)
GO
CREATE NONCLUSTERED INDEX [ixContactLastName] ON [Person].[Contact]
([LastName] ASC)
GO
For our first example, let's run a query to return all contacts with a LastName starting with C:
-- Statistics indicate too many rows for an index lookup
SELECT *
FROM Person.Contact
WHERE LastName like 'C%'
Despite the presence of a nonclustered index on
LastName, which in theory could be used for this query, SQL Server
correctly ignores it in favor of a clustered index scan. If we execute
this query in SQL Server Management Studio using the Include Actual
Execution Plan option (Ctrl+M, or select from the Query menu), we can
see the graphical representation of the query execution, as shown in figure 2.
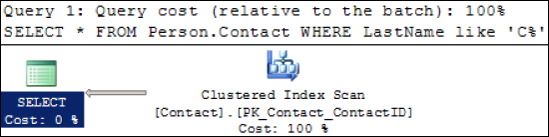
No great surprises here; SQL Server is
performing a clustered index scan to retrieve the results. Using an
index hint, let's rerun this query and force SQL Server to use the
ixContactLastName index:
-- Force the index lookup with an index hint
SELECT *
FROM Person.Contact WITH (index=ixContactLastName)
WHERE LastName like 'C%'
Looking at the graphical execution plan, we can confirm that the index is being used, as per figure 3.
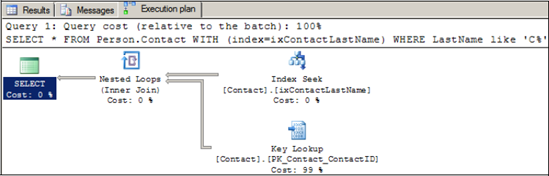
On a small database such as AdventureWorks, the
performance difference between these two methods is negligible; both
complete in under a second. To better understand how much slower the
index lookup method is, we can use the SET STATISTICS IO option, which returns disk usage statistics alongside the query results. Consider the script in listing 12.
Example 1. Comparing query execution methods
-- Compare the Disk I/O with and without an index lookup
SET STATISTICS IO ON
GO
DBCC DROPCLEANBUFFERS
GO
SELECT *
FROM Person.Contact
WHERE LastName like 'C%'
DBCC DROPCLEANBUFFERS
SELECT *
FROM Person.Contact with (index=ixContactLastName)
WHERE LastName like 'C%'
GO
|
This script will run the query with and without the index hint. Before each query, we'll clear the buffer cache using DBCC DROPCLEANBUFFERS to eliminate the memory cache effects. The STATISTICS IO option will produce, for each query, the number of logical, physical, and read-ahead pages, defined as follows:
Logical Reads—Represents the number of pages read from the data cache.
Physical Reads—If the required page is not in cache, it will be read from disk. It follows that this value will be the same or less than the Logical Reads counter.
Read Ahead Reads—The
SQL Server storage engine uses a performance optimization technique
called Read Ahead, which anticipates a query's future page needs and
prefetches those pages from disk into the data cache. In doing so, the
pages are available in cache when required, avoiding the need for the
query to wait on future physical page reads.
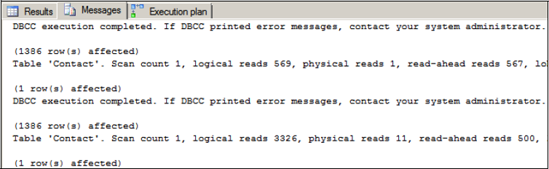
So with these definitions in mind, let's look at the STATISTICS IO output in figure 4.
These statistics make for some very interesting
reading. Note the big increase in logical reads (3326 versus 569) for
the second query, which contains the (index= ixContactLastName) hint. Why such a big increase? A quick check of sys.dm_ db_index_physical_stats, reveals there are only 570
pages in the table/clustered index. This is consistent with the
statistics from the query that used the clustered index scan. So how can
the query using the nonclustered index read so many more pages? The
answer lies in the key lookup.
What's actually occurring here is that a number
of clustered index pages are being read more than once. In addition to
reading the nonclustered index pages for matching records, each key
lookup reads pages from the clustered index to compete the query. In
this case, a number of the key lookups are rereading the same clustered
index page. Clearly a single clustered index scan is more efficient, and
SQL Server was right to ignore the nonclustered index.
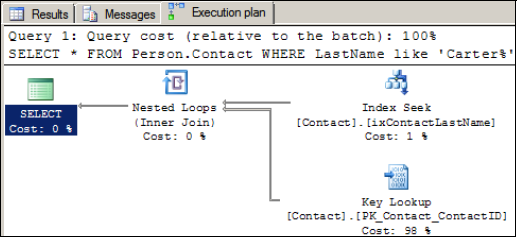
Let's move on to look at an example where SQL Server uses the nonclustered index without any index hints:
SELECT *
FROM Person.Contact
WHERE LastName like 'Carter%'
The graphical execution plan for this query is shown in figure 5, and it confirms the index is being used.
We can see that of the overall query cost, 98
percent is the key lookup. Eliminating this step will derive a further
performance increase. You'll note that in our queries so far we've been
using select *; what if we reduced the required columns for the
query to only those actually required and included them in the index?
Such an index is called a covering index.
Covering indexes
Let's assume we actually need only FirstName,
LastName, and EmailAddress. If we created a composite index containing
these three columns, the key lookup wouldn't be required. Let's modify
the index to include the columns and rerun the query:
-- Create a covering index
DROP INDEX [ixContactLastName] ON [Person].[Contact]
GO
CREATE NONCLUSTERED INDEX [ixContactLastName] ON [Person].[Contact]
(
[LastName] ASC
, [FirstName] ASC
, [EmailAddress] ASC
)
GO
SELECT LastName, FirstName, EmailAddress
FROM Person.Contact
WHERE LastName LIKE 'Carter%'
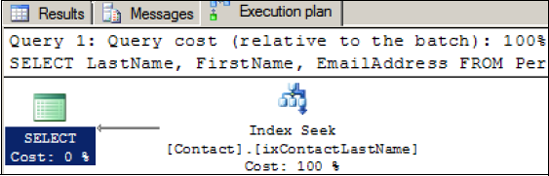
The execution plan from the query with the new index is shown in figure 6.
As you can see, the query is now satisfied from
the contents of the nonclustered index alone. No key lookups are
necessary, as all of the required columns are contained in the
nonclustered index. In some ways, this index can be considered a mini,
alternatively clustered version of the table.
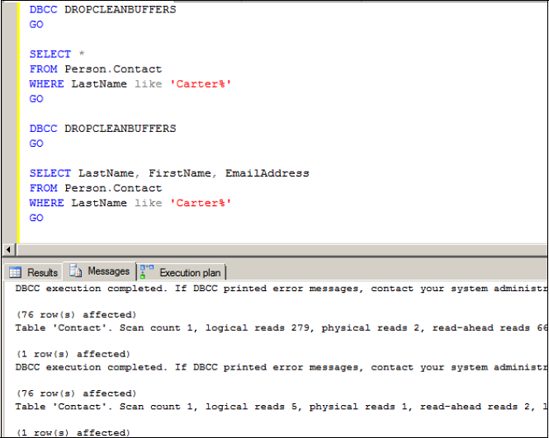
Confirming the improvement from a disk-statistics perspective, the logical reads drop significantly, from 279 to 5, as shown in figure 7.
Including additional columns in the nonclustered index to avoid the key lookup process makes it a covering index.
While this is an excellent performance-tuning technique, the one
downside is that the additional columns are included at all levels of
the index (root, all intermediate levels, and the leaf level). In our
query above, given that we're not using the additional columns as
predicates, that is, where clause conditions, they're not
required at any level of the index other than the leaf level to avoid
the key lookup. In small indexes, this is not really an issue. However,
for very large indexes, the additional space taken up by the additional
columns at each index level not only increases the index size but makes
the index seek process less efficient. The included columns feature,
introduced in SQL Server 2005, enhances covering indexes in several
ways.
Included columns
While they're a relatively simple and very
effective performance-tuning mechanism, covering indexes are not without
their limitations; there can be a maximum of 16 columns in a composite
index with a maximum combined size of 900 bytes. Further, columns of
certain data types, including n/varchar(max), n/varbinary(max), n/text,
XML, and image cannot be specified as index key columns.
Recognizing the value of covering indexes, SQL
Server 2005 and above circumvent the size and data type limitations
through indexes with included columns. Such indexes allow additional
columns to be added to the leaf level of nonclustered indexes. In doing
so, the additional columns are not counted in the 16 column and 900 byte
maximum, and additional data types are allowed for these columns
(n/varchar(max), n/varbinary(max), and XML). Consider the following create index statement:
-- Include columns at the leaf level of the index
CREATE NONCLUSTERED INDEX ixContactLastName
ON Person.Contact (LastName)
INCLUDE (FirstName, EmailAddress)
Notice the additional INCLUDE clause at
the end of the statement; this index will offer all the benefits of the
previous covering index. Further, if appropriate, we could add columns
with data types not supported in traditional indexes, and we wouldn't be
restricted by the 16-column maximum.
When deciding whether to place a column in the
index definition as a key column or as an included column, the
determining factor is whether the column will be used as a predicate,
that is, a search condition in the where clause of a query. If a column is added purely to avoid the key lookup because of inclusion in the select
list, then it makes sense for it to be an included column.
Alternatively, a column used for filtering/searching purposes should be
included as a key column in the index definition.
Let's take our previous example of a surname
search. If a common search condition was on the combination of surname
and first name, then it would make sense for both columns to be included
in the index as key columns for more efficient lookups when seeking
through the intermediate index levels. If the email address column is
used purely as return information, that is, in the query's select list, but not as a predicate (where clause condition), then it makes sense for it to be an included column. Such an index definition would look like this:
CREATE NONCLUSTERED INDEX ixContactLastName
ON Person.Contact (LastName, FirstName)
INCLUDE (EmailAddress)
In summary, included column indexes retain the
power of covering indexes while minimizing the index size and therefore
maximizing lookup efficiency.
Before closing our section on nonclustered index
design, let's spend some time covering an important new indexing
feature included in SQL Server 2008: filtered indexes.
Filtered indexes
Filtered indexes are one of my favorite new
features in SQL Server 2008. Before we investigate their many
advantages, consider the following table used to store customer details,
including a country code:
CREATE TABLE [Person].[Customer](
[CustomerID] [int] IDENTITY(1,1) PRIMARY KEY CLUSTERED
, [Title] [nvarchar](8) NULL
, [FirstName] [nvarchar](100) NOT NULL
, [LastName] [nvarchar](100) NOT NULL
, [EmailAddress] [nvarchar](100) NULL
, [CountryCode] char(2) NULL
)
GO
Let's imagine this table is part of a database
used around the globe on a 24/7 basis. The Customer table is used
predominantly by a follow-the-sun call center, where customer details
are accessed by call center staff from the same country or region as the
calling customers.
Creating a nonclustered index on this table
similar to the one earlier in the article where we included FirstName,
LastName, and EmailAddress will enable lookups on customer name to
return the required details. If this was a very large table, the size of
the corresponding nonclustered indexes would also be large. Maintaining large indexes that are in use 24/7
presents some interesting challenges.
In our example here, a traditional (full table)
index would be created similar to what we've already seen earlier in the article ; columns would be defined as key or included index columns,
ideally as part of a covering index. All is fine so far, but wouldn't it
be good if we could have separate versions of the index for specific
countries? That would enable, for example, the Australian version of the
index to be rebuilt when it's midnight in Australia and few, if any,
Australian users are being accessed. Such an index design would reduce
the impact on sections of users that are unlikely to be accessed at the
time of the index maintenance.
Consider the following two index-creation statements:
-- Create 2 filtered indexes on the Customer table
CREATE NONCLUSTERED INDEX ixCustomerAustralia
ON Person.Customer (LastName, FirstName)
INCLUDE (EmailAddress)
WHERE CountryCode = 'AU'
GO
CREATE NONCLUSTERED INDEX ixCustomerUnitedKingdom
ON Person.Customer (LastName, FirstName)
INCLUDE (EmailAddress)
WHERE CountryCode = 'UK'
GO
The indexes we've created here are similar to
ones from earlier in the article with one notable exception: they have a
predicate (where clause filter) as part of their definition.
When a search is performed using a matching predicate and index keys,
the query optimizer will consider using the index, subject to the usual
considerations. For example, the ixCustomerAustralia index could be used
for a query that includes the CountryCode = 'AU' predicate such as this:
SELECT FirstName, LastName, EmailAddress
FROM Person.Customer
WHERE
LastName = 'Colledge'
AND FirstName like 'Rod%'
AND CountryCode = 'AU'
Such indexes, known as filtered indexes, enable a whole range of benefits. Let's cover the major ones:
Segregated maintenance—As
we've discussed, creating multiple smaller versions of a single larger
index enables maintenance routines such as index rebuilds to be
scheduled in isolation from other versions of the index that may be
receiving heavy usage.
Smaller, faster indexes—Filtering
an index makes it smaller and therefore faster. Best of all, covered
filtered indexes support optimized lookups for specialized purposes.
Consider a very large product table with a ProductCategory column;
filtered indexes could be created for product categories, which include
the appropriate columns specific to that category. When combined with
application logic, such indexes enable fast, optimized lookups for
sections of data within a table.
Creating unique indexes on nullable columns—
Consider the Social Security number (SSN) column ; to support storing records for non-U.S. residents, we couldn't
define the column as NOT NULL. This would mean that a percentage of the records would have a NULL
SSN, but those that do have one should be unique. By creating a
filtered unique nonclustered index, we can achieve both of these goals
by defining the index with a WHERE SSN IS NOT NULL predicate.
More accurate statistics—Unless created with the FULLSCAN
option , statistics work by sampling a
subset of the index. In a filtered index, all of the sampled statistics
are specific to the filter; therefore they are more accurate compared to
an index that keeps statistics on all table data, some of which may
never be used for index lookups.
Lower storage costs—The ability to exclude unwanted data from indexes enables the size, and therefore storage costs, to be reduced.
Some of the advantages
of filtered indexes could be achieved in earlier versions of SQL Server
using indexed views. While similar, there are important differences and
restrictions to be aware of when choosing one method over the other.