4.3 Sequential Disk Access
Microsoft SQL Server and various
hardware manufacturers partner to provide guidance for data warehouse
systems. This program is called SQL Server Fast Track Data Warehouse. A
data warehouse system is designed to hold a massive amount of data. The
Fast Track program takes great care to design storage hardware that is
perfectly sized for a specific server platform.
The data warehouse is architected such that data
is sequentially loaded and sequentially accessed. Typically, data is
first loaded in a staging database. Then it is bulk loaded and ordered
so that queries generate a sequential table access pattern. This is
important because sequential disk access is far more efficient than
random disk access. Our 15,000-RPM disk drive will perform 180 random
operations or 1,400 sequential reads. Sequential operations are so much
more efficient than random access that SQL Server is specifically
designed to optimize sequential disk access.
In a worst-case scenario, SQL Server will read
64KB data extents and write 8K data pages. When SQL Server detects
sequential access it dynamically increases the request size to a
maximum size of 512KB. This has the effect of making the storage more
efficient.
Designing an application to generate
sequential disk access is a powerful cost-saving tool. Blending
sequential operations with larger I/O is even more powerful. If our
15,000-RPM disk performs 64KB random reads, it will generate about
12MBs per second. This same drive will perform 88MBs per second of
sequential 64KB reads. Changing the I/O size to 512KB will quickly
cause the disk drive to hit its maximum transfer rate of 600MBs per
second.
Increasing the I/O size has its limitations. Most
hardware RAID controllers are designed to optimally handle 128KB I/Os.
Generating I/Os that are too big will stress the system resources and
increase latency.
One example is a SQL Server backup job.
Out-of-the-box, SQL Server backup will generate 1,000KB I/Os. Producing
I/Os this large will cause a lot of stress and high latency for most
storage arrays. Changing the backup to use 512KB I/Os will usually
reduce the latency and often reduce the time required to complete the
backup. Each storage array is different, so be sure to try different
I/O sizes to ensure that backups run optimally.
Henk Van Der Valk has written several articles that highlight backup optimization:
http://henkvandervalk.com/how-to-increase-sql-database-full-backup-speed-using-compression-and-solid-state-disks
http://henkvandervalk.com/how-to-increase-the-sql-database-restore-speed-using-db-compression-and-solid-state-disks
This Backup statement will set the maximum transfer size to 512KB.
BACKUP DATABASE [DBName] TO DISK = N'E:\dump\BackupFile.bak'
WITH MAXTRANSFERSIZE=524288, NAME = BackupName
GO
4.4 Server Queues
Each physical disk drive can perform
one operation and can queue one operation. Aggregating disks into a
RAID set increases the pool of possible I/O. Because each physical disk
can perform two operations, a viable queue setting is determined by
multiplying the number of disks in a RAID set by two. A RAID set
containing 10 disk drives, for example, will work optimally with a
queue of 20 outstanding I/Os.
Streaming I/O requires a queue of I/Os to
continue operating at a high rate. Check the HBA settings in your
server to ensure they are maximized for the type of I/O your
application is generating. Most HBAs are set by the manufacturer to a
queue of 32 outstanding I/Os. Higher performance can often be achieved
by raising this value to its available maximum. The SQL Server FAST
Track program recommends that queue depth be set at 64.
Keep in mind that in a shared storage SAN
environment, the performance gains of one application are often
achieved at the cost of overall performance. As a SQL Server
administrator, be sure to advise your storage administrators of any
changes you are making.
4.5 File Layout
This section divides the discussion
about how to configure storage into traditional disk storage and
array-based storage pools. Traditional storage systems offer
predictable performance. You expect Online Transaction Processing
(OLTP) systems to generate random workload. If you know how many
transactions you need to handle, you can predict how many underlying
disks will be needed in your storage array.
For example, assume that you will handle 10,000
transactions, and your storage is made up of 10K SAS drives that are
directly attached to your server. Based on the math described earlier,
you know that a 10K SAS drive will perform about 140 IOPS; therefore,
you need 142 of them. Seventy-one disks would be enough to absorb 10K
reads, but you are going to configure a RAID 1+0 set, so you need
double the number of disks.
If you need to handle a lot of tempdb operations,
then you need to appropriately size the tempdb drive. In this case, you
are going to design tempdb to be about 20 percent of the expected I/O
for the main data files, so you expect 2,000 IOPS. This will require
that 28 disks in a RAID 1+0 configuration back the tempdb database.
You expect that a backup load will be entirely
sequential in nature. Remember that SATA drives perform sequential
operations extremely well, so they are a great candidate for dump
drives. These drives are usually less expensive and offer greater
capacity than SAS or Fibre Channel disks.
Large SATA disks store data in an extremely dense
format, which puts them at greater risk for a failure and at the same
time increases the chance that a second failure will occur before the
RAID system can regenerate data from the first failure. For this
reason, RAID 6 is an ideal candidate to protect the data drives. RAID 6
has the greatest performance overhead, so it is important to adjust the
backup I/O appropriately. In most cases backup I/O should not exceed a
512KB transfer size.
Finally, you need to plan for your log drives.
Logs are extremely latency sensitive. Therefore, you should completely
isolate the log onto its own set of RAID 1+0 SAS disk drives. You
expect sequential I/O, so the number of disks is governed by capacity
rather than random performance I/O.
Why wouldn’t you mix the log drive with the
backup drive? Sequential disk access assumes that the drive head enters
a track and reads sequential blocks. If you host applications that
sequentially access a set of disk drives, you will cause the disk drive
head to seek excessively.
This excessive head seeking is called large block random access. Excessive seeking can literally drop the potential IOPS by half:
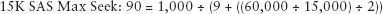
Isolating sequential performance not only applies
to log files. Within a database you can often identify specific data
tables that are sequentially accessed. Separating this sequential
access can greatly reduce the performance demand on a primary storage
volume.
In large databases with extremely heavy write
workloads, the checkpoint process can often overwhelm a storage array.
SQL Server checkpoints attempt to guarantee that a database can recover
from an unplanned outage within the default setting of one minute. This
can produce an enormous spike of data in an extremely short time.
We have seen the checkpoint process send 30,000
write IOPS in one second. The other 59 seconds are completely idle.
Because the storage array will likely be overwhelmed with this
workload, SQL Server is designed to dial back the I/O while trying to
maintain the one-minute recovery goal. This slows down the write
process and increases latency.
In SQL Server 2008 and 2008 R2, you can start SQL
Server with the –k command-line option (–k followed by a decimal
representing the maximum MB per second the checkpoint is allowed to
flush). This option can smooth the impact of a checkpoint at the
potential risk of a long recovery and changed writing behavior. SQL
Server 2012 includes a new feature called Indirect Checkpoint. The
following Alter Database statement will enable Indirect Checkpoint:
ALTER DATABASE
SET TARGET_RECOVERY_TIME = 60 SECONDS
Indirect Checkpoint has a smoothing
effect on the checkpoint process. If the system would normally flush
30K IOPS in one second, it will now write 500 IOPS over the one-minute
recovery interval. This feature can provide a huge savings, as it would
take 428 10K disks configured in a RAID 1+0 stripe to absorb the 30,000
I/O burst. With Indirect Checkpoint you can use only eight disks. As
with any new database feature, ensure that you fully test this
configuration prior to turning it loose in a production environment.
Many organizations use shared storage arrays and
thin storage pools to increase storage utilization. Keep in mind that
storage pools amalgamate not only capacity, but also performance. We
have previously recommended that data, log, backup, and temporary
database files be isolated onto their own physical storage. When the
storage is shared in a storage pool, however, this isolation no longer
makes sense.
The current reason for separation is to protect
the data, diversifying it across failure domains. In other words, don’t
keep all your eggs in one basket. It is advisable to ensure that
database backups and physical data reside on different storage groups,
or even different storage arrays.
Many IT groups maintain separate database,
server, networking, and storage departments. It is important that you
communicate the expected database performance requirements to the
storage team so they can ensure that the shared storage arrays are
designed to handle the load.
Once your application is running on a shared thin
storage pool, performance monitoring is critical. Each of the
applications is intertwined. Unfortunately, many systems are active at
the exact same time — for example, end of month reporting. If your
application negatively impacts other applications, it is often more
beneficial and cost effective to move it out of the shared storage
environment and onto a separate system.
4.6 Partition Alignment
Windows versions prior to Windows
Server 2008 did not properly align Windows Server partitions to the
underlying storage geometry. Specifically, the Windows hidden sector is
63KB in size. NTFS allocation units default to 4K and are always
divisible by 2. Because the hidden sector is an odd size, all of the
NTFS allocation units are offset. This results in the possibility of
generating twice the number of NTFS requests.
Any partition created using the Windows 2008 or
newer operating systems will automatically create sector alignment. If
a volume is created using Windows 2003 or older operating systems, it
has the possibility of being sector unaligned. Unfortunately, a
misaligned partition must be recreated to align it properly.
For more information on sector alignment, please see this blog post: http://sqlvelocity.typepad.com/blog/2011/02/windows-disk-alignment.html.
4.7 NTFS Allocation Unit Size
When formatting a partition you are
given the option to choose the allocation unit size, which defaults to
4KB. Allocation units determine both the smallest size the file will
take on disk and the size of the Master File Table ($MFT). If a file is
7KB in size, it will occupy two 4KB allocation clusters.
SQL Server files are usually large. Microsoft
recommends the use of a 64KB allocation unit size for data, logs, and
tempdb. Please note that if you use allocation units greater than 4KB,
Windows will disable NTFS data compression (this does not affect SQL
Server compression).
It is more efficient to create fewer larger
clusters for large SQL Server files than it would be to create more
small-size clusters. While large clusters are efficient for a few small
files, the opposite is true for hosting a lot of small files. It is
possible to run out of clusters and waste storage capacity.
There are exceptions to these cluster size best
practices. When using SQL Server FILESTREAM to store unstructured data,
ensure that the partition used to host FILESTREAM data is formatted
with an appropriate sector size, usually 4K. SQL Server Analysis
Services (SSAS) will read and write cube data to small XML files and
should therefore also utilize a 4K-sector size.
4.8 Flash Storage
So far, you have seen that hard disk
drives are mechanical devices that provide varying performance
depending on how the disk is accessed. NAND (Not AND memory which is a
type of electronic based logic gate)-based flash storage is an
alternative technology to hard disks. Flash has no moving parts and
therefore offers consistent read performance that is not affected by
random I/O.
Flash drives are significantly more expensive
than traditional hard disks, but this cost is offset by their I/O
performance. A single 15K disk drive will only perform about 180 IOPS,
whereas a single flash drive can perform 20,000 or more. Because you
often need to trade capacity for performance, the flash drives offer a
potentially huge cost savings. You can conceivably replace 220 15K disk
drives configured in a RAID 1+0 set with two flash drives!
The ideal scenario for flash disks is when you
have an application that has a relatively small dataset and an
extremely high performance requirement. A high-transaction OLTP
database or SQL Server Analysis Services data cube are excellent
examples of applications that can take advantage of the increased
random flash performance.
NAND flash drives are most efficient when
responding to read requests. Writing to a flash disk is a more complex
operation that takes longer than a read operation. Erasing a NAND data
block is an even more resource-intensive operation. Blending reads and
writes will reduce the potential performance of the flash drive. If a
disk is capable of 20,000 or 30,000 reads, it may only be able to
sustain 5,000 writes.
Not all flash is created equally. Flash memory is
created in both single (SLC) and multi-layer (MLC) technology. SLC
memory is more expensive to manufacture but offers higher performance.
MLC is manufactured using multiple stacked cells that share a single
transistor. This enables MLC to be manufactured more economically, but
it has the drawback of lowering performance and increasing the
potential failure rate.
Enterprise MLC (eMLC) is a newer generation of
flash technology that increases the reliability and performance of
multi-level flash. Before choosing a type of flash, it is important to
understand the number of reads and writes that your flash will be
subjected to. The acts of writing and erasing from flash cells degrade
the cells over time. Flash devices are built with robust error
correcting and checking, but they will fail due to heavy write cycles.
Ensure that the flash technology you implement will survive your
application performance requirements. Unfortunately, flash devices are
not a one-size-fits-all solution. If your application generates an
extremely high number of random I/O requests, flash will probably
perform well. Conversely, if your application creates a few large
requests, such as a data warehouse application, then you won’t
necessarily see a great benefit.
Several manufacturers sell a flash-based PCI
express NAND flash device. These cards offer extremely low latency at
high I/O rates. A single card will respond in tens of microseconds and
generate hundreds of thousands of IOPS. Contrast this with a shared
array that responds in hundreds of microseconds, or even milliseconds.
If your application can generate this type of I/O load, these cards can
greatly increase your potential performance. Not only can the card
sustain hundreds of thousands of I/Os, each is returned much faster.
This can relieve many SQL blocking issues.
We stress that your application must be able to
generate appropriate I/O because we have seen many instances in which
customers have installed flash as a panacea only to be disappointed
with low performance increases. If a given application is hampered by
poor design, throwing money at it in the form of advanced technology
will not always fix the problem!
There are now hybrid PCI express–based solutions
that combine server software, the PCI express flash card, and shared
storage arrays. These systems monitor I/O access patterns. If a given
workload is deemed appropriate, data will be stored and accessed on the
PCI express flash card. To maintain data integrity, the data is also
stored on the shared storage array. This hybrid approach is useful for
extremely large datasets that simply won’t fit on a series of server
flash cards. In addition, SAN features such as replication can be
blended with new technology.
Many shared storage arrays offer flash solutions
that increase array cache. These systems work just like the PCI express
hybrid solution, except the flash is stored inside the shared storage
array. Appropriate data is migrated to the flash storage, thereby
increasing its performance. As stated before, if the access pattern is
deemed not appropriate by the array, data will not be moved. Heavy
write bursts are one example. A massive checkpoint that attempts to
write 30,000 IOPS will probably never be promoted to flash because the
accessed data changes every minute!
Shared storage arrays blend tiering and automated
tiering with flash drives. When you consider most databases, only a
subset of the data is in use at any given time. In an OLTP system, you
care about the data that is newly written and the data you need to
access over a short window of time to derive metrics. Once a sales
quarter or year has passed, this data is basically an archive.
Some DBAs migrate this archive data.
Automated tiering offers a low-overhead system that actively monitors
data use. Active data is promoted to a flash storage tier; moderately
accessed data is migrated to a FC or SAS tier; and archival data is
automatically stored on high-capacity SATA.