David
Hayward goes deep, deep undercover. Into the hidden depths of the invisible web
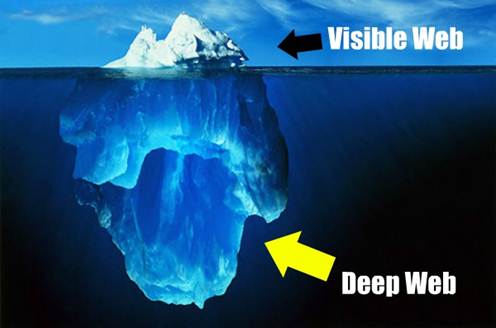
The Deep Web (also
called Deepnet, the invisible Web, DarkNet, ...
‘How on
earth do we access the invisible areas of the internet?’
Many of us
are quite content to go about our business on the web, happily searching away,
safe in the knowledge that pretty much everything we’re looking for is right at
our finger tips.
However,
despite how web savvy you may think you are, you’re only scratching the surface
of the World Wide Web. Much like the analogy of the iceberg, the web only shows
us its upper third portion, while below, the other two thirds exist in a dark
and hidden realm, known collectively as the invisible web.
The term
‘invisible web’ was first coined by Like Bergman the founder of BrightPlanet, a
site dedicated to harvesting this hidden invisible web – or deep web as it’s
also known.
Basically,
the invisible web is classed as the area of the internet that’s not scanned by
the web-bots, spiders and indexing tools of the likes of Google, Yahoo! or any
of the other popular search engines. These normal indexing agents are capable
of grabbing content via the many hyperlinks, keywords and other methods that
make up the surface web, or the area of the internet that we normally surf on
an average day.
However,
when we talk about the invisible web we’re referring to the likes of scientific
journals, minutes taken during meetings, vast databases of libraries,
public-fronted intranets of companies – the list goes on. In fact, it’s
estimated that the size of the surface web is in the region of 300TB, whereas
the estimated size of the invisible web is 98PB (that’s petabytes, by the way)
and growing at a considerable rate. In 1997 the Library of Congress was
estimated to have close to 4PB of ‘invisible’ data within its searchable,
queried databases.
How on
earth do we access these invisible areas of the internet, where the web
crawlers fear to tread? It’s relatively easy, as it happens.
Deep searching
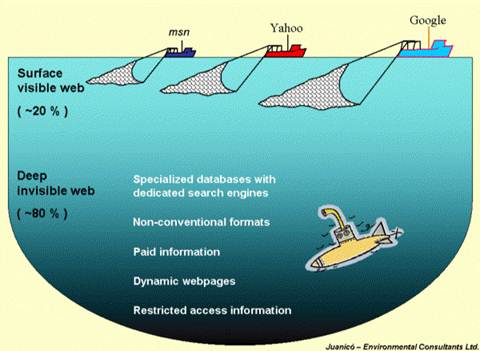
Search the deep web
What we
need to start with is a search engine that can collate and penetrate deep into
the invisible web, of which there are many. Some are used for the greater good,
providing us with the latest scientific knowledge and theses, while others are
used by unscrupulous individuals who inhabit the darkened recesses of the
internet and host sites that will not be mentioned in this magazine. Obviously,
it’s the former we’ll be looking at (leaving the latter to the business end of
a stout stick) here, and to do so we’ll have a look at a variety of different,
unique, search engines that allow us to delve into the invisible web.
InfoMine

Infomine, a well-made
search engine that’s pretty accurate, when trawling the invisible web
The first
of these are the ‘Scholarly Internet Resource Collections’ known as InfoMine. A
virtual library of resources relevant to scientists, students and researchers,
InfoMine can trawl the otherwise hidden databases, e-journals, e-books,
bulletin boards, mailing lists and online library card catalogues for
information that would normally be well and truly obscured within the
traditional confines of a surface Google search.
InfoMinehas
been built by librarians from the University of California, Wake Forest
University, the California State University and the University of Detroit using
a range of web crawlers and metadata assignment. The web crawlers used in this
project are the NalandaiVia Focused Crawler, the InfoMine Virtual Library
Crawler and the InfoMine Automatic Focused Crawler, with each of these crawlers
targeting a different arm of the internet’s available resources within the iVia
software project (ivia.urc.edu).
The
metadata assignment modules classify fields from the incredibly powerful
Library of Congress databases, with some clever algorithms involving keyphrase
identification and extraction. All in all, the effect is both stunning and vast
– see for yourself by pointing your browser to infomine.urc.edu. As an example,
enter the following into the search bar: Manhattan Project. The results shown
range from a scientific journal of the physics behind the first nuclear weapon
to other papers concerning the cost of nuclear weaponry to the US,
congressional research reports, technical information from OSTI (Office of
Scientific and Technical Information) and the Hiroshima Archives.
It’s
fascinating stuff, ideal for those who are trying to drill down to more
specific and not often viewed information.