SQL Server has two main types
of indexes: clustered and nonclustered. They both help the query engine
get at data faster, but they have different effects on the storage of
the underlying data. The following sections describe these two main
types of indexes and provide some insight into when to use each type.
Clustered Indexes
Clustered indexes sort and
store the data rows for a table, based on the columns defined in the
index. For example, if you were to create a clustered index on the LastName and FirstName
columns in a table, the data rows for that table would be organized or
sorted according to these two columns. This has some obvious advantages
for data retrieval. Queries that search for data based on the clustered
index keys have a sequential path to the underlying data, which helps
reduce I/O.
A clustered index is
analogous to a filing cabinet where each drawer contains a set of file
folders stored in alphabetical order, and each file folder stores the
files in alphabetical order. Each file drawer contains a label that
indicates which folders it contains (for example, folders A–D). To
locate a specific file, you first locate the drawer containing the
appropriate file folders, then locate the appropriate file folder within
the drawer, and then scan the files in that folder in sequence until
you find the one you need.
A clustered index is structured as a balanced tree (B-tree). Figure 1 shows a simplified diagram of a clustered index defined on a last name column.
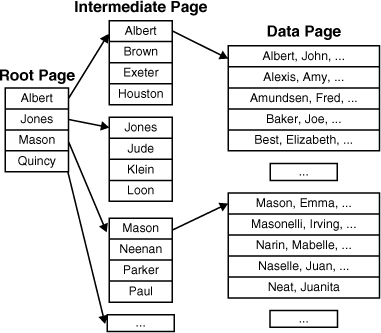
The top, or root, node is a single
page where searches via the clustered index are started. The bottom
level of the index is the leaf nodes. With a clustered index, the leaf
nodes of the index are also the data pages of the table. Any levels of
the index between the root and leaf nodes are referred to as intermediate nodes.
All index key values are stored in the clustered index levels in sorted
order. To locate a data row via a clustered index, SQL Server starts at
the root node and navigates through the appropriate index pages in the
intermediate levels of the index until it reaches the data page that
should contain the desired data row(s). It then scans the rows on the
data page until it locates the desired value.
There can be only one
clustered index per table. This restriction is driven by the fact that
the underlying data rows can be sorted and stored in only one way. With
very few exceptions, every table in a database should have a clustered
index. The selection of columns for
a clustered index is very important and should be driven by the way the
data is most commonly accessed in the table. You should consider using
the following types of columns in a clustered index:
Those that are often accessed sequentially
Those that contain a large number of distinct values
Those that are used in range queries that use operators such as BETWEEN, >, >=, <, or <= in the WHERE clause
Those that are frequently used by queries to join or group the result set
When you are using these
criteria, it is important to focus on the most critical data access: the
queries that are run most often or that must have the best performance.
This approach can be challenging but ultimately reduces the number of
data pages and related I/O for the queries that matter.
Nonclustered Indexes
A nonclustered index is
a separate index structure, independent of the physical sort order of
the data rows in the table. You are therefore not restricted to creating
only 1 nonclustered index per table; in fact, in SQL Server 2008 you
can create up to 999 nonclustered indexes per table. This is an increase
from SQL Server 2005, which was limited to 249.
A nonclustered index is
analogous to an index in the back of a book. To find the pages on which a
specific subject is discussed, you look up the subject in the index and
then go to the pages referenced in the index. With nonclustered
indexes, you may have to jump around to many different nonsequential
pages to find all the references.
A nonclustered index is also structured as a B-tree. Figure 2 shows a simplified diagram of a nonclustered index defined on a first name column.
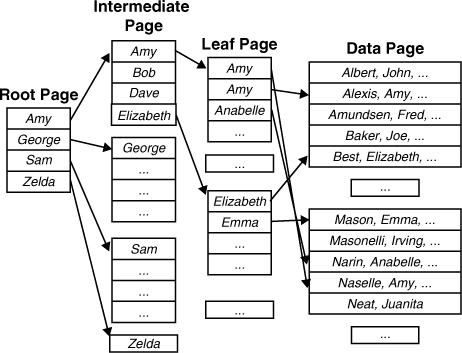
As with a clustered
index, in a nonclustered index, all index key values are stored in the
nonclustered index levels in sorted order, based on the index key(s).
This sort order is typically different from the sort order of the table
itself. The main difference between a nonclustered index and clustered
index is that the leaf row of a nonclustered index is independent of the
data rows in the table. The leaf level of a nonclustered index contains
a row for every data row in the table, along with a pointer to locate
the data row. This pointer is either the clustered index key for the
data row, if the table has a clustered index on it, or the data page ID
and row ID of the data row if the table is stored as a heap structure
(that is, if the table has no clustered index defined on it).
To locate a data row via a
nonclustered index, SQL Server starts at the root node and navigates
through the appropriate index pages in the intermediate levels of the
index until it reaches the leaf page, which should contain the index key
for the desired data row. It then scans the keys on the leaf page until
it locates the desired index key value. SQL Server then uses the
pointer to the data row stored with the index key to retrieve the
corresponding data row.
Note
For
a more detailed discussion of clustered tables versus heap tables (that
is, tables with no clustered indexes) and more detailed descriptions of
clustered and nonclustered index key structures and index key rows, as
well as how SQL Server internally maintains indexes.
The efficiency of the
index lookup and the types of lookups should drive the selection of
nonclustered indexes. In the book index example, a single page reference
is a very simple lookup for the book reader and requires little work.
If, however, many pages are referenced in the index, and those pages are
spread throughout the book, the lookup is no longer simple, and much
more work is required to get all the information.
You should choose your
nonclustered indexes with the book index example in mind. You should
consider using nonclustered indexes for the following:
Queries that do not return large result sets
Columns that are frequently used in the WHERE clause that return exact matches
Columns that have many distinct values (that is, high cardinality)
All columns referenced in a critical query (a special nonclustered index called a covering index that eliminates the need to go to the underlying data pages)
Having
a good understanding of your data access is essential to creating
nonclustered indexes. Fortunately, SQL Server comes with tools such as
the SQL Server Profiler and Database Engine Tuning Advisor that can help
you evaluate your data access paths and determine which columns are the
best candidates.