5. Circular Replication
After reading about dual masters, you might wonder if it is possible to
set up a multimaster with more than two masters replicating to each
other. Since each slave can only have a single master, it is only
possible to get this by setting up replication in a circular
fashion.
Although this is not a recommended setup, it is certainly
possible. The reason it is not recommended is because it is very hard to
get it to work correctly in the presence of failure. The reasons for
this will become clear in a moment.
Using a circular replication setup with three or more servers can
be quite practical for reasons of locality. As a real-life example,
consider the case of a mobile phone operator with subscribers all over
Europe. Since the mobile phone owners travel around quite a lot, it is
convenient to have the registry for the customers close to the actual
phone, so by placing the data centers at some strategic places in
Europe, it is possible to quickly verify call data and also register new
calls locally. The changes can then be replicated to all the servers in
the ring, and eventually all servers will have accurate billing
information. In this case, circular replication is a perfect setup: all
subscriber data is replicated to all sites, and updates of data are
allowed in all data centers.
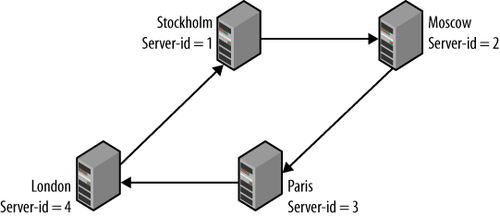
Setting up circular replication (as shown in Figure 10) is quite easy. Example 16 provides a script that sets
up circular replication automatically, so where are the complications?
As in every setup, you should ask yourself, “What happens when something
goes wrong?”
Example 16. Setting up circular replication
def circular_replication(server_list):
count = len(server_list)
for i in range(0, count):
change_master(server_list[(i+1) % count], server_list[i])
|
In Figure 10, there are four
servers named for the cities in which they are located (the names are
arbitrarily picked and do not reflect a real setup). Replication goes in
a circle: “Stockholm” to “Moscow” to “Paris” to “London” and back to
“Stockholm.” This means that “Moscow” is upstream of “Paris,” but
downstream of “Stockholm.” Suppose that “Moscow” goes down suddenly and
unexpectedly. To allow replication to continue, it is necessary to
reconnect the “downstream” server “Paris” to the “upstream” server
“Stockholm” to ensure the continuing operation of the system.
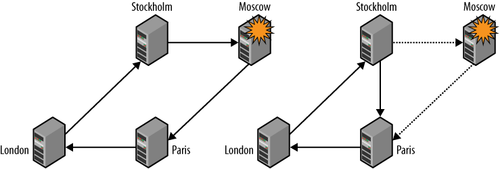
Figure 11 shows
a scenario in which a single server fails and the servers reconnect to
allow replication to continue. Sounds simple enough, doesn’t it? Well,
it’s not really as simple as it looks. There are basically three issues
that you have to consider:
The downstream server—the server that was slave to the failed
master—needs to connect to the upstream server and start replication
from what it last saw. How is that position decided?
Suppose that the crashed server has managed to send out some
events before crashing. What happens with those events?
We need to consider how we should bring the failed server into
the topology again. What if the server applied some transactions of
its own that were written to the binary log but not yet sent out? It
is clear that these transactions are lost, so we need to handle
this.
When detecting that one of the servers failed, it is easy to use
the CHANGE MASTER command
to connect the downstream server to the upstream server, but for
replication to work correctly, we must determine the right position. To
find the correct position, use binary log scanning techniques similar to
what we used for slave promotion. However, in this case, we have several
servers to consider when deciding what position to start from. The
Last_Exec_Trans table introduced earlier already
contains the server ID and the global transaction ID seen from that server.
The second problem is more complicated. If the failing server
managed to send out an event, there is nothing that can remove that
event from the replication stream, so it will circle around the
replication topology forever. If the statement is idempotent—it can be
reapplied multiple times without causing problems—the situation could be
manageable for a short period, but in general, the statement has to be
removed somehow.
In MySQL version 5.5, the parameter IGNORE_SERVER_IDS was added to the CHANGE MASTER
command. This parameter allows a server to remove more events from the
replication stream than just the events with the same server ID as the
server. So, assuming that the servers have the IDs shown in Figure 11, we can reconnect
Paris to Stockholm using the following command:
paris> CHANGE MASTER TO
-> MASTER_HOST='stockholm.example.com',
-> IGNORE_SERVER_IDS = (2);
For versions of MySQL earlier than version 5.5, there is no such
support and you may have to devise some other means of removing the
offending events. The easiest method is probably to bring in a server
temporarily with the same ID as the crashed server for the sole purpose
of removing the offending event.
The complete procedure to shrink the ring in a circular
setup—assuming that you are using MySQL 5.5—is as follows:
Determine the global transaction IDs of the last committed
transactions on the downstream server for all servers that are still
up and running.
paris> SELECT Server_ID, Trans_ID FROM Last_Exec_Trans WHERE Server_ID != 2;
+-----------+----------+
| Server_ID | Trans_ID |
+-----------+----------+
| 1 | 5768 |
| 3 | 4563 |
| 4 | 768 |
+-----------+----------+
3 rows in set (0.00 sec)
Scan the binary log of the upstream server for the last of the
global transaction IDs seen in
Last_Exec_Trans.
Connect the downstream server to this position using CHANGE
MASTER.
paris> CHANGE MASTER TO
-> MASTER_HOST='stockholm.example.com',
-> IGNORE_SERVER_IDS = (2);
Since the failed server can be in an alternative future compared
to the other servers, the safest way to bring it into the circle again
is to restore the server from one of the servers in the ring and
reconnect the circle so that the new server is in the ring again. The
steps to accomplish that are:
Restore the server from one of the existing servers—the server
that will eventually be the upstream server—in the ring and attach
it as a slave to that server.
moscow> CHANGE MASTER TO MASTER_HOST='stockholm.example.com';
Query OK, 0 rows affected (0.18 sec)
moscow> START SLAVE;
Query OK, 0 rows affected (0.00 sec)
Once the server has caught up sufficiently, break the ring by
disconnecting the downstream server. This server will no longer
receive any updates.
paris> STOP SLAVE;
Query OK, 0 rows affected (0.00 sec)
Since the restored server might not have all the events that
the downstream server has, it is necessary to wait for the restored
server to have at least all the events the downstream server has.
Since the positions are for the same server, you can do this using a
combination of SHOW SLAVE STATUS
and MASTER_POS_WAIT.
paris> SHOW SLAVE STATUS;
...
Relay_Master_Log_File: stockholm-bin.000096
...
Exec_Master_Log_Pos: 756648
1 row in set (0.00 sec)
moscow> SELECT MASTER_POS_WAIT('stockholm-bin.000096', 756648);
+-------------------------------------------------+
| MASTER_POS_WAIT('stockholm-bin.000096', 756648) |
+-------------------------------------------------+
| 985761 |
+-------------------------------------------------+
1 row in set (156.32 sec)
Determine the position of the event on the restored server by
scanning the binary log of the restored server for the global ID
that was last seen by the downstream server.
Connect the downstream server to the restored server and start
replication.
paris> CHANGE MASTER TO
-> MASTER_HOST='moscow.example.com',
-> MASTER_LOG_FILE='moscow-bin.000107',
-> MASTER_LOG_POS=196758,
Query OK, 0 rows affected (0.18 sec)
moscow> START SLAVE;
Query OK, 0 rows affected (0.00 sec)