2.2. Replicated disks using DRBD
The Linux High
Availability project contains a lot of useful tools for maintaining high
availability systems. Most of these tools are beyond the scope of this
book, but there is one tool that is interesting for our purposes: DRBD
(Distributed Replicated Block Device), which is software for
replicating block devices over the network.
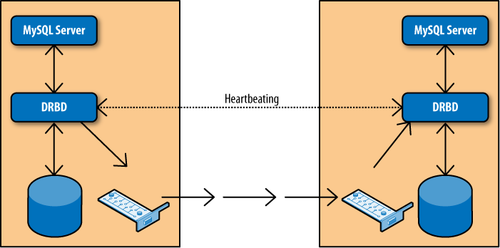
Figure 5 shows a typical
setup of two nodes where DRBD is used to replicate a disk to a
secondary server. The setup creates two DRBD block devices, one on
each node, which in turn write the data to the real disks. The two
DRBD processes communicate over the network to ensure any changes made
to the primary are replicated over to the secondary. To the MySQL
server, the device replication is transparent. The DRBD devices look
and behave like normal disks, so no special configuration is needed
for the servers.
You can only use DRBD in an active-passive setup, meaning that the passive disk
cannot be accessed at all. In contrast with the shared disk solution
outlined earlier and the bidirectional replication implementation
described later in this chapter, the passive master cannot be used—not
even for pure read-only tasks.
Similar to the shared disk solution, DRBD has the advantage of
not needing to translate positions between the two masters since they
share the same files. However, failing over to the standby master
takes longer than in the shared disk setup described earlier.
For both the shared disk and the DRBD setup, it is necessary to
perform recovery of the database files before bringing the servers
online. Since recovery of MyISAM tables is quite expensive, it is recommended that
you use a transactional engine with good recovery performance for the
database tables—InnoDB is the proven solution in this case, but other
transactional engines such as PBXT are maturing quickly, so investigating the
alternatives is well-invested time.
Since the mysql database contains strictly
MyISAM tables, you should, as a general principle, avoid unnecessary
changes to these tables during normal operations. It is, of course,
impossible to avoid when you need to perform administrative
tasks.
One advantage of DRBD over shared disks is that for the shared
disk solution, the disks actually provide a single point of failure.
Should the network to the shared disk array go down, it is possible
that the server will not work at all. In contrast, replicating the
disks means that the data is available on both servers, which reduces
the risk of a total failure.
DRBD also has support built in to handle split-brain syndrome and can be configured to
automatically recover from it.
2.3. Bidirectional replication
When using dual masters in an active-passive setup, there are no significant
differences compared to the hot standby solution outlined earlier.
However, in contrast to the other dual-masters solutions outlined
earlier, it is possible to have an active-active setup (shown in Figure 6).
Although controversial in some circles, an active-active setup does have its uses. A typical case
is when there are two offices working with local information in the
same database—for example, sales data or employee data—and want low
response times when working with the database, while ensuring the data
is available in both places. In this case, the data is naturally local
to each office—for example, each salesperson is normally working with
his own sales and rarely, if ever, makes changes to another
salesperson’s data.
Use the following steps to set up bidirectional
replication:
Ensure both servers have different server IDs.
Ensure both servers have the same data (and that no changes
are made to either system until replication has been
activated).
Create a replication user and prepare replication on both
servers.
Start replication on both servers.
Warning:
When using bidirectional replication, be forewarned that
replication includes no concept of conflict resolution. If both
servers update the same piece of data, you will have a conflict that
may or may not be noticed. If you are lucky, replication will stop
at the offending statement, but you shouldn’t count on it. If you
intend to have a high availability system, you should ensure at the
application level that two servers do not try to update the same
data.
Even if data is naturally partitioned—as in the example given
previously with two offices in separate locations—it is critical to
put provisions in place to ensure data is not accidentally updated
at the wrong server.
In this case the application has to connect to the server
responsible for the employee and update the information there, not
just update the information locally and hope for the best.
If you want to connect slaves to either of the servers, you have
to ensure the log-slave-updates
option is enabled. Since the other master is also connected as a
slave, an obvious question is: what happens with events that the
server sends out when they return to the server?
When replication is running, the server ID of the server that created the event is
attached to each event. This server ID is then propagated further when
the slave writes the event to its binary log. When a server sees an
event with the same server ID as its own server ID, that event is
simply skipped and replication proceeds with the next event.
Sometimes, you want to process the event anyway. This might be
the case if you have removed the old server and created a new one with
the same server ID and you are in the process of performing a PITR. In
those cases, it is possible to disable this checking using
the replicate-same-server-id configuration
variable. However, to prevent you from shooting yourself in the foot,
you cannot set this option at the same time that log-slave-updates is set. Otherwise, it
would be possible to send events in a circle and quickly thrash all
the servers. To prevent that from happening, it is not possible to
forward events when using replicate-same-server-id.
When using an active-active setup, there is a need to handle
conflicts in a safe way, and by far the easiest way—and the only
recommended way to handle an active-active setup—is to ensure the different active
servers write to different areas.
One possible solution is to assign different databases—or
different tables—to different masters. Example 3 shows a setup that
uses two different tables, each updated by different masters. To make
it easy to view the split data, a view is created that combines the
two tables.
Example 3. Different tables for different offices
CREATE TABLE Employee_Sweden (
uid INT AUTO_INCREMENT PRIMARY KEY,
name VARCHAR(20)
);
CREATE TABLE Employee_USA (
uid INT AUTO_INCREMENT PRIMARY KEY,
name VARCHAR(20)
);
-- This view is used when reading from the two tables simultaneously.
CREATE VIEW Employee AS
SELECT 'Swe', uid, name FROM Employee_Sweden
UNION
SELECT 'USA', uid, name FROM Employee_USA;
|
This approach is best to use if the split is natural in that,
for example, different offices have different tables for their local
data and the data only needs to be combined for reporting purposes.
This might seem easy enough, but the following issues can complicate
usage and administration of the tables:
Reads and writes to different tables
Because of the way the view is defined, you cannot update
it. Writes have to be directed at the real tables, while reads
can either use the view or read directly from the tables.
It might therefore be necessary to introduce application
logic to handle the split into reads and writes that go to
different tables.
Accurate and current data
Since the two tables are managed by different sites,
simultaneous updates to the two tables will cause the system to
temporarily enter a state where both servers have information
that is not available on the other server. If a snapshot of the
information is taken at this time, it will not be
accurate.
If accurate information is required, generate methods for
ensuring the information is accurate. Since such methods are
highly application-dependent, they will not be covered
here.
Optimization of views
When using views, two techniques are available to construct a result
set. In the first method—called MERGE—the view is expanded in place,
optimized, and executed as if it was a SELECT query. In the second
method—called TEMPTABLE—a temporary table is
constructed and populated with the data.
If the server uses a TEMPTABLE view, it performs very
poorly, whereas the MERGE
view is close to the corresponding SELECT. MySQL uses TEMPTABLE whenever the view definition
does not have a simple one-to-one mapping between the rows of
the view and the rows of the underlying table—for example, if
the view definition contains UNION, GROUP
BY, subqueries, or aggregate functions—so careful
design of the views is paramount for getting good performance.
In either case, you have to consider the implications of
using a view for reporting, since it might affect
performance.
If each server is assigned separate tables, there will be no
risk of conflict at all since updates are completely separated.
However, if all the sites have to update the same tables, you will
have to use some other scheme.
The MySQL server has special support for handling this situation
in the form of two server variables:
auto_increment_offset
This variable controls the starting value for any
AUTO_INCREMENT column in a
table. This is the value that the first row inserted into the
table gets for the AUTO_INCREMENT column. For
subsequent rows, the value is calculated using auto_increment_increment.
auto_increment_increment
This is the increment used to compute the next value of an
AUTO_INCREMENT column.
Note:
There are session and global versions of these two variables
and they affect all tables on the server, not just the tables
created. Whenever a new row is inserted into a table with an
AUTO_INCREMENT column, the next
value available in the sequence below is used:
valueN =
auto_increment_offset +
N*auto_increment_increment
Notice that the next value is not
computed by adding the auto_increment_increment to the last
value in the table.
Use auto_increment_offset and
auto_increment_increment to ensure
new rows added to a table are assigned numbers from different
sequences of numbers depending on which server is used. The idea is
that the first server uses the sequence 1, 3, 5… (odd numbers), while
the second server uses the sequence 2, 4, 6… (even numbers).
Continuing with Example 3, Example 4 uses these two
variables to ensure the two servers use different IDs when inserting
new employees into the Employee table.
Example 4. Two servers writing to the same table
-- The common table can be created on either server
CREATE TABLE Employee (
uid INT AUTO_INCREMENT PRIMARY KEY,
name VARCHAR(20),
office VARCHAR(20)
);
-- Setting for first master
SET GLOBAL AUTO_INCREMENT_INCREMENT = 2;
SET GLOBAL AUTO_INCREMENT_OFFSET = 1;
-- Setting for second master
SET GLOBAL AUTO_INCREMENT_INCREMENT = 2;
SET GLOBAL AUTO_INCREMENT_OFFSET = 2;
|
This scheme handles the insertion of new items in the tables,
but when entries are being updated, it is still critical to ensure the
update statements are sent to the correct server—the server
responsible for the employee. Otherwise, data is likely to be
inconsistent. If updates are not done correctly, the slaves will
normally not stop—they will just replicate the information, which
leads to inconsistent values on the two servers.
For example, if the first master executes the statement:
master-1> UPDATE Employee SET office = 'Vancouver' WHERE uid = 3;
Query OK, 1 rows affected (0.00 sec)
and at the same time, the same row is updated at the second
server using the statement:
master-2> UPDATE Employee SET office = 'Paris' WHERE uid = 3;
Query OK, 1 rows affected (0.00 sec)
the result will be that the first master will place the employee
in Paris while the second master will place the employee in Vancouver
(note that the order will be swapped since each server will update the
other server’s statement after its own).
Detecting and preventing such inconsistencies is important
because they will cascade and create more inconsistency over time.
Statement-based replication executes statements based on the data in
the two servers, so one inconsistency can lead to others.
If you take care to separate the changes made by the two servers
as outlined previously, the row changes will be replicated and the two
masters will therefore be consistent.
If users use different tables on the different servers, the
easiest way to prevent such mistakes to assign privileges so that a
user cannot accidentally change tables on the wrong server. This is,
however, not always possible and cannot prevent the case just
shown.