Data Mining Predictions Using DMX
DMX is a powerful
tool for mining structure and mining model DDL queries, but you can also
use it to write what are arguably data mining’s most valuable asset:
prediction queries. The next six DMX script files in the Chapter20DMX
project provide examples of such prediction queries. Using special DMX
prediction functions, you can apply the results from data patterns
discovered by your mining models to new data.
The basic format of a prediction query is as follows:
SELECT <select expression list>
FROM <model>
PREDICTION JOIN
<source data query>
ON <join mapping list>
For specific queries, replace <model> with the mining model on which you want to base the query predictions and replace <source data query> with the data to which you want to apply the prediction. Often you will replace <source data query> with an OPENQUERY statement similar to those used in the SELECT INTO DMX modeling statements for binding the data mining columns to the source data. You can replace <select expression>
with any combination of columns returned in the source data query,
predictable columns from the mining model, and DMX prediction functions
that return a column of data, including a nested table column. Replace <join mapping list>
with the column mapping between the source data and the input columns
of the mining model. The LeastLikelyCar.dmx script contains the
following code:
SELECT TOP 250
t.FirstName
,t.LastName
,t.Phone
,PredictProbability([Is Car Owner],'N') AS ProbNotCarOwner
FROM CarOwner_DT
PREDICTION JOIN
OPENQUERY([Adventure Works DW],
'SELECT
c.FirstName
,c.LastName
,tc.*
FROM vCustomerProfitability tc
INNER JOIN dimCustomer c
ON tc.CustomerKey = c.CustomerKey')
AS t
ON t.Gender = CarOwner_DT.Gender AND
t.IncomeGroup = CarOwner_dt.[Income Group] AND
t.MaritalStatus = CarOwner_dt.[Marital Status] AND
t.Region = CarOwner_dt.Region
ORDER BY PredictProbability([Is Car Owner],'N') DESC
By using the TOP and ORDER BY
clauses supported by DMX, the query returns the names and phone numbers
of the 250 people in vCustomerProfitability who are least likely to own
a car according to the CarOwner_DT decision trees mining model we
created earlier. The query uses the PredictProbability()
function, which takes two arguments: a predictable column from the
mining model and a specified value for the column. The function returns
the probability of not owning a car, as predicted by the CarOwner_DT
model.
Execute the query, and
you’ll see that the 250 customers least likely to own a car all have a
78-percent probability of not owning a car. The CarOwner_DT model
predicts car ownership based on gender, income group, marital status,
and region. Many customers in the database will have the same values for
those characteristics. Customers who share a characteristic that is
important for determining car ownership will have the same predicted
probability of owning a car. To see the next-highest probability of not
owning a car, try selecting a larger number of customers, say, the “TOP
1250.”
When the column names in the model and the source data query are the same, DMX allows the use of a NATURAL PREDICTION JOIN. When you use a NATURAL PREDICTION JOIN, you do not have to specify an ON
clause for the prediction query. SSAS joins the model and source data
based on column names. The script file NaturalPredictionJoin.dmx
provides a simple example:
SELECT TOP 250
t.FirstName
,t.LastName
,t.Phone
,PredictProbability([Is Car Owner],'N') AS ProbNotCarOwner
FROM CarOwner_DT
NATURAL PREDICTION JOIN
OPENQUERY([Adventure Works DW],
'SELECT
c.FirstName
,c.LastName
,tc.Phone
,tc.Gender
,tc.IncomeGroup AS [Income Group]
,tc.MaritalStatus AS [Marital Status]
,tc.Region
FROM vCustomerProfitability tc
INNER JOIN dimCustomer c
ON tc.CustomerKey = c.CustomerKey')
AS t
ORDER BY PredictProbability([Is Car Owner],'N') DESC
Execute the query in NaturalPredictionJoin.dmx and verify that the results are the same as for LeastLikelyCar.dmx.
To be considered a match by the NATURAL PREDICTION JOIN,
the names in the model and source data query must be identical. If the
source data query does not have a column with a name identical to that
of an input column, no error message is returned; instead, SSAS makes
the prediction based on the columns for which matches are
found. The query in NaturalPredictionJoinMissingMappings.dmx does not
alias the column names in the source data query to match the names from
the mining model.
SELECT TOP 250
t.FirstName
,t.LastName
,t.Phone
,PredictProbability([Is Car Owner],'N') AS ProbNotCarOwner
FROM CarOwner_DT
NATURAL PREDICTION JOIN
OPENQUERY([Adventure Works DW],
'SELECT
c.FirstName
,c.LastName
,tc.Phone
,tc.Gender
,tc.IncomeGroup
,tc.MaritalStatus
,tc.Region
FROM vCustomerProfitability tc
INNER JOIN dimCustomer c
ON tc.CustomerKey = c.CustomerKey')
AS t
ORDER BY PredictProbability([Is Car Owner],'N') DESC
In
this query, the prediction is made based only on columns in which there
is an exact match in the name (Gender and Region, in this case).
Execute the script file NaturalPredictionJoinMissingMappings.dmx and
note how the results of the statement in it differ from those of the
previous two.
When the model has a
nested table column, the queries are slightly more complex but have the
same basic structure of joining a data mining model with source data and
specifying the mapping of the source data columns to the input columns
of the mining model. The complexity of the query comes primarily in the
source data query. The query must return a result set with an embedded
table column. As you will recall from the DMX modeling statements we
looked at earlier, this is done using the SHAPE command.
MostLikelyCluster5.dmx provides an example of a DMX prediction query using a model with a nested table column:
SELECT TOP 250
t.FirstName
,t.LastName
,t.Profit
,ClusterProbability('Cluster 5') AS ProbCluster5
FROM CustomerProfitCategory_CL5
PREDICTION JOIN
SHAPE {
OPENQUERY([Adventure Works DW],
'SELECT
c.FirstName
,c.LastName
,tc.*
FROM vCustomerProfitability tc
INNER JOIN dimCustomer c
ON tc.CustomerKey = c.CustomerKey
ORDER BY tc.CustomerKey'
)
}
APPEND({
OPENQUERY([Adventure Works DW],
'SELECT
CustomerKey
,ProductCategory
FROM vCustomerPurchases
ORDER BY CustomerKey'
)}
RELATE CustomerKey TO CustomerKey)
AS PurchaseCategory
AS t
ON t.Age = CustomerProfitCategory_CL5.Age AND
t.CommuteDistance = CustomerProfitCategory_CL5.[Commute Distance] AND
t.EnglishEducation = CustomerProfitCategory_CL5.[English Education] AND
t.Gender = CustomerProfitCategory_CL5.Gender AND
t.HasKidsAtHome = CustomerProfitCategory_CL5.[Has Kids At Home] AND
t.IncomeGroup = CustomerProfitCategory_CL5.[Income Group] AND
t.IsCarOwner = CustomerProfitCategory_CL5.[Is Car Owner] AND
t.IsHomeOwner = CustomerProfitCategory_CL5.[Is Home Owner] AND
t.IsNewCustomer = CustomerProfitCategory_CL5.[Is New Customer] AND
t.MaritalStatus = CustomerProfitCategory_CL5.[Marital Status] AND
t.NumProdGroup = CustomerProfitCategory_CL5.[Num Prod Group] AND
t.RecencyGroup = CustomerProfitCategory_CL5.[Recency Group] AND
t.Region = CustomerProfitCategory_CL5.Region AND
t.PurchaseCategory.ProductCategory =
CustomerProfitCategory_CL5.[v Customer Purchases].[Product Category]
ORDER BY ClusterProbability('Cluster 5') DESC
The
query uses the CustomerProfitCategory_CL5 clustering mining model to
predict the probability that a customer will be in cluster 5—this is the
cluster with a relatively high concentration of high-profit customers,
some of whom are likely to be new customers.
We are interested in
customers who are likely to be in this cluster because we’d like to keep
them as customers. The above query returns a list of customers,
including the dollar profit amount generated from each customer and the
probability that the customer is in cluster 5. Execute the query; a
portion of the result set returned by the query is shown in Figure 4.
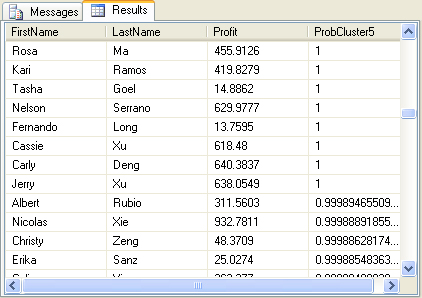
The query uses the ClusterProbability()
prediction function, which takes a specific cluster as an argument and
returns the probability that the input record belongs to the specified
cluster.
You can also return a (nested) table column in a SELECT statement. For example, the clustering algorithm supports the use of the PredictHistogram()
function with a clustering column argument. This returns a table column
with the predicted probability of each record in the result set being
in each cluster. This is illustrated in the query in script file
Cluster5ProbabilityDist.dmx:
SELECT TOP 250
t.FirstName
,t.LastName
,t.Profit
,Cluster()
,PredictHistogram(Cluster())
FROM CustomerProfitCategory_CL5
PREDICTION JOIN
SHAPE {
OpenQuery([Adventure Works DW],
'SELECT
c.FirstName
,c.LastName
,tc.*
FROM vCustomerProfitability tc
INNER JOIN dimCustomer c
ON tc.CustomerKey = c.CustomerKey
ORDER BY tc.CustomerKey'
)
}
APPEND({
OPENQUERY([Adventure Works DW],
'SELECT
CustomerKey
,ProductCategory
FROM vCustomerPurchases
ORDER BY CustomerKey'
)}
RELATE CustomerKey To CustomerKey)
AS PurchaseCategory
AS t
ON t.Age = CustomerProfitCategory_CL5.Age AND
t.CommuteDistance = CustomerProfitCategory_CL5.[Commute Distance] AND
t.EnglishEducation = CustomerProfitCategory_CL5.[English Education] AND
t.Gender = CustomerProfitCategory_CL5.Gender AND
t.HasKidsAtHome = CustomerProfitCategory_CL5.[Has Kids At Home] AND
t.IncomeGroup = CustomerProfitCategory_CL5.[Income Group] AND
t.IsCarOwner = CustomerProfitCategory_CL5.[Is Car Owner] AND
t.IsHomeOwner = CustomerProfitCategory_CL5.[Is Home Owner] AND
t.IsNewCustomer = CustomerProfitCategory_CL5.[Is New Customer] AND
t.MaritalStatus = CustomerProfitCategory_CL5.[Marital Status] AND
t.NumProdGroup = CustomerProfitCategory_CL5.[Num Prod Group] AND
t.RecencyGroup = CustomerProfitCategory_CL5.[Recency Group] AND
t.Region = CustomerProfitCategory_CL5.Region AND
t.PurchaseCategory.ProductCategory =
CustomerProfitCategory_CL5.[v Customer Purchases].[Product Category]
Execute
the query to see how SQL Server Management Studio handles nested
tables. You will notice that each cell of the predicted cluster
histogram column (the last one) has a plus sign. Click one of them to
expand the nested table for its row. The result will appear as shown in Figure 5. For example, Aimee He has a 76-percent probability of being in cluster 5 and a 24-percent probability of being in cluster 1.
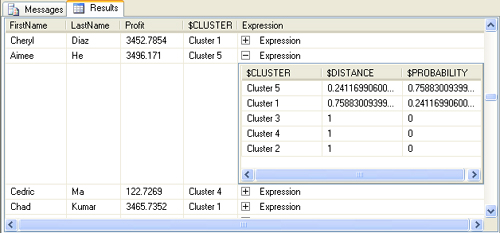
The results from a
query with a nested table column are rich and interesting but might be
difficult for many applications to manipulate. To address this concern,
DMX has a FLATTENED keyword that allows you to return the nested table column within a nonhierarchical result set, even while using the SHAPE
command to obtain the nested data. The query in the script file
Cluster5ProbabilityDistFlattened.dmx returns almost the same result as
that in Cluster5ProbabilityDist.dmx, except that it uses the FLATTENED
keyword to return a nonhierarchical result set. It also specifies that
the top 1250 records should be returned instead of the top 250. Each row
in the nonflattened result set has an equivalent five rows (one for
each segment of the histogram) in the flattened result set; therefore,
to see the same data we have to request five times the number of records
as before:
SELECT FLATTENED TOP 1250
t.FirstName
,t.LastName
,t.Profit
,ClusterProbability()
,PredictHistogram(Cluster())
FROM CustomerProfitCategory_CL5
PREDICTION JOIN
SHAPE {
OpenQuery([Adventure Works DW],
'SELECT
c.FirstName
,c.LastName
,tc.*
FROM vCustomerProfitability tc
INNER JOIN dimCustomer c
ON tc.CustomerKey = c.CustomerKey
ORDER BY tc.CustomerKey'
)
}
APPEND({
OPENQUERY([Adventure Works DW],
'SELECT
CustomerKey
,ProductCategory
FROM vCustomerPurchases
ORDER BY CustomerKey'
)}
RELATE CustomerKey To CustomerKey)
AS PurchaseCategory
AS t
ON t.Age = CustomerProfitCategory_CL5.Age AND
t.CommuteDistance = CustomerProfitCategory_CL5.[Commute Distance] AND
t.EnglishEducation = CustomerProfitCategory_CL5.[English Education] AND
t.Gender = CustomerProfitCategory_CL5.Gender AND
t.HasKidsAtHome = CustomerProfitCategory_CL5.[Has Kids At Home] AND
t.IncomeGroup = CustomerProfitCategory_CL5.[Income Group] AND
t.IsCarOwner = CustomerProfitCategory_CL5.[Is Car Owner] AND
t.IsHomeOwner = CustomerProfitCategory_CL5.[Is Home Owner] AND
t.IsNewCustomer = CustomerProfitCategory_CL5.[Is New Customer] AND
t.MaritalStatus = CustomerProfitCategory_CL5.[Marital Status] AND
t.NumProdGroup = CustomerProfitCategory_CL5.[Num Prod Group] AND
t.RecencyGroup = CustomerProfitCategory_CL5.[Recency Group] AND
t.Region = CustomerProfitCategory_CL5.Region AND
t.PurchaseCategory.ProductCategory =
CustomerProfitCategory_CL5.[v Customer Purchases].[Product Category]
Execute the query; the results should appear as in Figure 6.
Each column of the nested table now appears as a column of the parent
table. The values in the non–table columns of the parent table are now
repeated for each row of the nested table. It is important to realize
that this flattened view of the nested table’s columns is a perfectly
valid view of the data, given that the nested table is itself considered
a column of its parent.
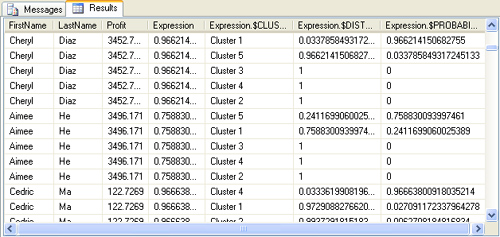
DMX Templates
Management Studio
offers templates for writing DMX queries. To see the templates, choose
View, Template Explorer in Management Studio. By default, SQL templates
are shown. Click the Analysis Server button on the Template Explorer
toolbar (the middle button, with the cube icon) to bring up a tree view
of the Analysis Services Templates. Expand the DMX node to see the DMX templates. The Template Explorer with the tree view of DMX templates is shown in Figure 7.
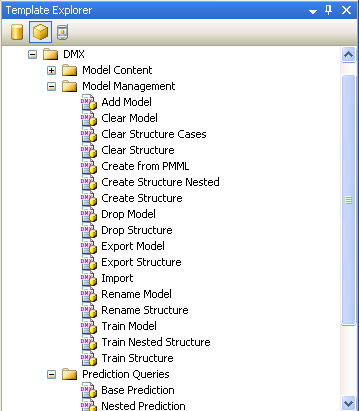
SSAS offers
templates for three types of DMX statements: Model Content, Model
Management, and Prediction Queries. Under the Model Content node, you
can find templates for writing queries to return metadata about your
mining models (essentially the same information presented by the viewer
controls, but without the visualizations). Under the Model Management
node are templates for writing queries to create and train mining
models, such as the ones we wrote earlier. Under the Prediction Queries
node are templates for writing prediction queries. The templates provide
a boilerplate for writing some of the most common DMX queries and are a
time-saving alternative to writing queries from scratch.