To exploit a blind SQL injection vulnerability you must first locate a potentially vulnerable point in the target application and verify that SQL injection is possible.
Forcing Generic Errors
Applications will often replace database errors with a generic error page, but even the presence of an error page can allow you to infer whether SQL injection is possible. The simplest example is the inclusion of a single-quote character in a piece of data that is submitted to the Web application. If the application produces a generic error page only when the single quote or a variant thereof is submitted, a reasonable chance of attack success is possible. Of course, a single quote would cause the application to fail for other reasons (e.g., where an application defense mechanism limits the input of single quotes), but by and large the most common source of errors when a single quote is submitted is a broken SQL query.
Injecting Queries with Side Effects
Stepping toward confirmation of the vulnerability, it is generally possible to submit queries that have side effects the attacker can observe. The oldest technique uses a timing attack to confirm that execution of the attacker’s SQL has occurred, and it is also sometimes possible to execute operating system commands whose output is observed by the attacker. For example, in Microsoft SQL Server it is possible to generate a five-second pause with the following SQL snippet:
WAITFOR DELAY '0:0:5'
Likewise, MySQL users could use the SLEEP( ) function which performs the same task in MySQL 5.0.12 and later.
Finally, the observed output can also be in-channel. For instance, if the injected string
' AND '1'='2
is inserted into a search field and produces a different response from
' OR '1'='1
then SQL injection appears very likely. The first string introduces an always false clause into the search query, which will return nothing, and the second string ensures that the search query matches every row.
Splitting and Balancing
Where generic errors or side effects are not useful, you can also try the “parameter splitting and balancing” technique (as named by David Litchfield), which is a staple of many blind SQL injection exploits. Splitting occurs when the legitimate input is broken up, and balancing ensures that the resultant query does not have trailing single quotes that are unbalanced. The basic idea is to gather legitimate request parameters and then modify them with SQL keywords so that they are different from the original data, although functionally equivalent when parsed by the database. By way of example, imagine that in the URL http://www.victim.com/view_review.aspx?id=5 the value of the id parameter is inserted into an SQL statement to form the following query:
SELECT review_content, review_author FROM reviews WHERE id=5
If you substitute 2+3 in place of 5, the input to the application will be different from the original request, but the SQL will be functionally equivalent:
SELECT review_content, review_author FROM reviews WHERE id=2+3
This is not limited to numeric data. Assume that the URL http://www.victim.com/count_reviews.jsp?author=MadBob returns information relating to a particular database entry, where the value of the author parameter is placed into an SQL query to produce the following:
SELECT COUNT(id) FROM reviews WHERE review_author='MadBob'
It is possible to split the string MadBob with database-specific operators that provide different inputs to the application that correspond to MadBob. An Oracle exploit using the || operator to concatenate two strings is:
MadB'||'ob
This yields the following SQL query:
SELECT COUNT(id) FROM reviews WHERE review_author='MadB'||'ob'
which is functionally equivalent to the first query.
Finally, Litchfield also pointed out that the technique could be used to create exploit strings that are virtually context-free. By using the splitting and balancing technique in combination with subqueries, it is possible to form exploits that are usable in many scenarios without modification. The following MySQL queries will produce the same output:
SELECT review_content, review_author FROM reviews WHERE id=5
SELECT review_content, review_author FROM reviews WHERE id=10—5
SELECT review_content, review_author FROM reviews WHERE id=5+(SELECT 0/1)
In the final SQL statement, a subquery was inserted and underlined. Since any subquery could be inserted at this point, the splitting and balancing technique provides a neat wrapper for injecting more complex queries that actually extract data. However, MySQL does not allow you to split and balance string parameters (since it lacks a binary string concatenation operator), restricting the technique to numeric parameters only. Microsoft SQL Server, on the other hand, does permit the splitting and balancing of string parameters, as the following equivalent queries show:
SELECT COUNT(id) FROM reviews WHERE review_author='MadBob'
SELECT COUNT(id) FROM reviews WHERE review_author='Mad'+CHAR(0x42)+'ob'
SELECT COUNT(id) FROM reviews WHERE review_author='Mad'+SELECT('B')+'ob'
SELECT COUNT(id) FROM reviews WHERE review_author='Mad'+(SELECT('B'))+'ob'
SELECT COUNT(id) FROM reviews WHERE review_author='Mad'+(SELECT '')+'Bob'
The last statement contains a superfluous underlined subquery that you could replace with a more meaningful exploit string, as you will see shortly. A clear advantage of the split and balance approach is that even if the exploit string is inserted into a stored procedure call, it will still be effective.
Table 1 provides a number of split and balanced strings that contain a subquery placeholder “…” for MySQL, Microsoft SQL Server, and Oracle. In each string, space is reserved for the original parameter value (either <number>, <string>, or <date> depending on the parameter’s type), and a subquery that returns NULL or an empty string in the “…” placeholder.
Warning
Logical operators, although useable, are not suitable for numeric parameters as they depend on the value of
Common Blind SQL Injection Scenarios
Here are three common scenarios in which blind SQL injection is useful:
-
When submitting an exploit that renders the SQL query invalid a generic error page is returned, while submitting correct SQL returns a page whose content is controllable to some degree. This is commonly seen in pages where information is displayed based on the user’s selection; for example, a user clicks a link containing an id parameter that uniquely identifies a product in the database, or the user submits a search request. In both cases, the user can control the output provided by the page in the sense that either a valid or an invalid identifier could be submitted, which would affect what was retrieved and displayed.
Because the page provides feedback (albeit not in the verbose database error message format), it is possible to use either a time-based confirmation exploit or an exploit that modifies the data set displayed by the page. Oftentimes, simply submitting a single quote is enough to unbalance the SQL query and force the generic error page, which helps in inferring the presence of an SQL injection vulnerability.
-
A generic error page is returned when submitting an exploit that renders the SQL query invalid, while submitting correct SQL returns a page whose content is not controllable. You might encounter this when a page has multiple SQL queries but only the first query is vulnerable and it does not produce output. A second common instance of this scenario is SQL injection in UPDATE or INSERT statements, where submitted information is written into the database and does not produce output, but could produce generic errors.
Using a single quote to generate the generic error page might reveal pages that fall into this category, as will time-based exploits, but content-based attacks are not successful.
-
Submitting broken or incorrect SQL does not produce an error page or influence the output of the page in any way. Because errors are not returned in this category of blind SQL injection scenarios time-based exploits or exploits that produce out-of-band side effects are the most successful at identifying vulnerable parameters.
Blind SQL Injection Techniques
Having looked at the definition of blind SQL injection as well as how to find this class of vulnerabilities, it is time to delve into the techniques by which these vulnerabilities are exploited. The techniques are split into two categories: inference techniques and alternative or out-of-band channel techniques. The former describes a set of attacks that use SQL to ask questions about the database and slowly extract information by inference, one bit at a time, and the latter uses mechanisms to directly extract large chunks of information through an available out-of-band channel.
Choosing which technique is best for a particular vulnerability depends on the behavior of the vulnerable resource. The types of questions you might ask are whether the resource returns a generic error page on submission of broken SQL snippets, and whether the resource allows you to control the output of the page to some degree.
Inference Techniques
At their core, all the inference techniques can extract at least one bit of information by observing the response to a specific query. Observation is key, as the response will have a particular signature when the bit in question is 1 and a different response when the bit is 0. The actual difference in response depends on the inference device you choose to use, but the chosen means are almost always based on response time, page content, or page errors, or a combination of these.
Inference techniques allow you to inject a conditional branch into an SQL statement, offering two paths where the branch condition is rooted in the status of the bit you are interested in. In other words, you insert a pseudo IF statement into the SQL query: IF x THEN y ELSE z. Typically, x (converted into the appropriate SQL) says something along the lines of “Is the value of Bit 2 of Byte 1 of Column 1 of Row 1 equal to 1?” and y and z are two separate branches whose behavior is sufficiently different that the attacker can infer which branch was taken. After the inference exploit is submitted, the attacker observes which response was returned, yz. If the y branch was followed the attacker knows the value of the bit was 1; otherwise, the bit was 0. The same request is then repeated, except that the next bit under examination is shifted one over. or
Keep in mind that the conditional branch does not have an explicit conditional syntax element such as an IF statement. Although it is possible to use a “proper” conditional statement, this will generally increase the complexity and length of the exploit; often you can get equivalent results with simpler SQL that approximates a formal conditional statement.
The bit of extracted information is not necessarily a bit of data stored in the database (although that is the common usage); you can also ask questions such as “Are we connecting to the database as the administrator?” or “Is this an SQL Server 2005 database?” or “Is the value of a given byte greater than 127?” Here the bit of information that is extracted is not a bit of a database record; rather, it is configuration information or information about data in the database. However, asking these questions still relies on the fact that you can supply a conditional branch into the exploit so that the answer to the question is either TRUE or FALSE. Thus, the inference question is an SQL snippet that returns TRUE or FALSE based on a condition supplied by the attacker.
Let’s distill this into a concrete example using a simple technique. We’ll focus on an example page, count_chickens.aspx, which is used to track the well-being of chicken eggs on an egg farm. Each egg has an entry in the chickens table, and among various columns is the status column that takes the value Incubating for unhatched eggs. The counting page has a status parameter that is vulnerable to blind SQL injection. When requested, the page queries the database with the following SELECT statement (where $input takes its value from the status parameter):
SELECT COUNT(chick_id) FROM chickens WHERE status='$input'
We want to extract the username that the page uses to connect to the database. Our Microsoft SQL Server database has a function called SYSTEM_USER that will return the login username in whose context the database session has been established. Normally, you can view this with the SQL SELECT SYSTEM_USER, but in this case the results are not visible. Figure 1 depicts an attempt to extract data using the verbose error message technique, but the page returns a standard error page. Unfortunately, the developers followed bad security advice, and rather than steering clear of dynamic SQL they chose to catch database exceptions and display a generic error message.
Figure 1. Unsuccessful Attempt to Extract Data through Error Messages
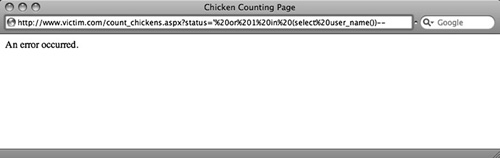
When we submit status=Incubating the page executes the preceding SQL query and returns the string shown in Figure 2.
Figure 2. Response When Counting Unhatched Eggs
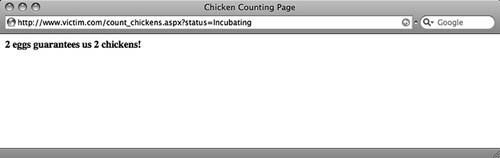
We can alter the status parameter such that the SQL query returns an empty result set by adding the “always false” clause and ‘1’= ‘2 to the legitimate query, yielding the following SQL statement:
SELECT COUNT(chick_id) FROM chickens WHERE status='Incubating' and '1'='2'
Figure 3 shows the response to this query. From the message, we can infer that the query returned an empty result set. Keep in mind that for two rows, status was Incubating, but the trailing false clause ensured that no rows would match.
Figure 3. Forcing an Empty Result Set
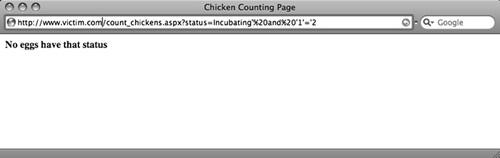
This is a classic example of blind SQL injection, as no errors are returned to us, but we can still inject SQL into the query and we can alter the results returned to us (either we get an egg count or we get “No eggs have that status”).
Now, instead of inserting an always false clause, we can insert a clause that is sometimes true and sometimes false. Because we are trying to derive the database username, we can ask whether the first character of the login is a by submitting status=Incubating’ and SUBSTRING(SYSTEM_USER,1,1)=’a which generates the following SQL statement:
SELECT COUNT(chick_id) FROM chickens WHERE status='Incubating' and
SUBSTRING(SYSTEM_USER,1,1)='a'
This SQL snippet will extract the first character from the output of system_user using the substring( ) function.
If the first character is indeed a, the second clause is true and we would see the same result from Figure 2; if the character is not a, the second clause is false and an empty result set would be returned, which would yield the message shown in Figure 5.3. Assuming that the first character was not a, we then submit a second page query with our custom status parameter asking whether the first character is b and so forth until the first character is found:
status=Incubating' AND SUBSTRING(SYSTEM_USER,1,1)='a (False)
status=Incubating' AND SUBSTRING(SYSTEM_USER,1,1)='b (False)
status=Incubating' AND SUBSTRING(SYSTEM_USER,1,1)='c (False)
⋮
status=Incubating' AND SUBSTRING(SYSTEM_USER,1,1)='s (True)
The False and True conditions are states that are inferred by the content on the page after each request is submitted, and do not refer to content within the page; that is, if the response contains “No eggs…” the state was False; otherwise, the state was True.
Let’s now shift our attention to the second character and repeat the process, starting at the letter a and moving through the alphabet. As each successive character is found, the search moves on to the next character. The page queries that reveal the username on our sample page are as follows:
status=Incubating' AND SUBSTRING(SYSTEM_USER,1,1)='s (True)
status=Incubating' AND SUBSTRING(SYSTEM_USER,2,1)='q (True)
status=Incubating' AND SUBSTRING(SYSTEM_USER,3,1)='l (True)
status=Incubating' AND SUBSTRING(SYSTEM_USER,4,1)='0 (True)
status=Incubating' AND SUBSTRING(SYSTEM_USER,5,1)='5 (True)
Simple, isn’t it? The username is sql05. Unfortunately, though, it’s actually not that simple, and we have skipped over a pretty important question: How do we know when the end of the username has been reached? If the portion of the username discovered so far is sql05, how can we be sure that there is not a sixth, seventh, or eighth character? The SUBSTRING( ) function will not generate an error if you ask it to provide characters past the end of the string; instead, it returns the empty string “. Therefore, we can include the empty string in our search alphabet, and if it is found we can conclude that the end of the username has been found.
status=Incubating' AND SUBSTRING(SYSTEM_USER,6,1)=' (True)
Hooray! Except that this is not very portable and depends on the explicit behavior of a particular database function. A neater solution would be to determine the length of the username before extracting it. The advantage of this approach, apart from being applicable to a wider range of scenarios than the “SUBSTRING( ) returns empty string” approach, is that it enables the attacker to estimate the maximum time that could possibly be spent extracting the username. We can find the length of the username with the same technique we employed to find each character, by testing whether the value is 1, 2, 3, and so on until we find a match:
status=Incubating' AND LEN(SYSTEM_USER)=1-- (False)
status=Incubating' AND LEN(SYSTEM_USER)=2-- (False)
status=Incubating' AND LEN(SYSTEM_USER)=3-- (False)
status=Incubating' AND LEN(SYSTEM_USER)=4-- (False)
status=Incubating' AND LEN(SYSTEM_USER)=5-- (True)
From this sequence of requests it was possible to infer that the length of the username was 5. Note as well the use of the SQL comment (—) that, although not required, makes the exploit a little simpler.
It is worth reinforcing the point that the inference tool used to determine whether a given question was TRUE or FALSE was the presence of either an egg count or a message stating that no eggs matched the given status. The mechanism by which you make an inference decision is highly dependent on the scenario that faces you and can often be substituted with a number of differing techniques.
Increasing the Complexity of Inference Techniques
It may have occurred to you that testing each character in the username against the entire alphabet (plus digits and possibly non-alphanumeric characters) is a pretty inefficient method for extracting data. To retrieve the username we had to request the page 112 times (five times for the length and 19, 17, 12, 27, and 32 times for the characters s, q, l, 0, and 5, respectively). A further consequence of this approach is that when retrieving binary data we could potentially have an alphabet of 256 characters, which sharply increases the number of requests and in any case is often not binary-safe. Two methods can improve the efficiency of retrieval through inference: a bit-by-bit method and a binary search method. Both methods are binary-safe.
The binary search method is mostly used to infer the value of single bytes without having to search through an entire alphabet. It successively halves the search space until the value of the byte is identified, by playing a game of eight questions. (Because a byte can have one of 256 values, the value will always be determined in eight requests. This is intuitively demonstrated by counting the number of times you can successively divide 256 in half before you get a non-integer quotient.) Assume that the byte we are interested in has the value 14. We ask questions and infer the answers through a convenient inference mechanism, which will return Yes if the answer is true and No if the answer is false. The game then proceeds like this:
-
Is the byte greater than 11? Yes, because 14 > 11.
-
Is the byte greater than 13? Yes, because 14 > 13.
-
Is the byte greater than 14? No, because 14 = 14.
Since the byte is greater than 13 but not greater than 14, we can infer that the byte has the value 14. This technique relies on a database function to provide the integer value of any byte; under Microsoft SQL Server, MySQL, and Oracle, this is provided by the ASCII( ) function.
If we return to the original problem of finding the database username, but now we use the binary search technique to find the first character of the username, we would like to execute the following SQL statement:
SELECT COUNT(chick_id) FROM chickens WHERE status='Incubating' AND ASCII(SUBSTRING(system_user,1,1))>127--'
We need to issue eight SQL statements to absolutely determine the character’s value. Converting all these queries into a page requests produces the following:
status=Incubating' and ASCII(SUBSTRING(SYSTEM_USER,1,1))>127-- (False)
status=Incubating' AND ASCII(SUBSTRING(SYSTEM_USER,1,1))>63-- (True)
status=Incubating' AND ASCII(SUBSTRING(SYSTEM_USER,1,1))>95-- (True)
status=Incubating' AND ASCII(SUBSTRING(SYSTEM_USER,1,1))>111-- (True)
status=Incubating' AND ASCII(SUBSTRING(SYSTEM_USER,1,1))>119-- (False)
status=Incubating' AND ASCII(SUBSTRING(SYSTEM_USER,1,1))>115-- (False)
status=Incubating' AND ASCII(SUBSTRING(SYSTEM_USER,1,1))>113-- (True)
status=Incubating' AND ASCII(SUBSTRING(SYSTEM_USER,1,1))>114-- (True)
From this series of requests, we can infer that the byte value of the first character of the username is 115, which, when converted to its ASCII table equivalent, is s. Using this technique it is possible to extract a byte in exactly eight requests, which is a vast improvement over comparing the full byte against an alphabet. If we add a third state to the request (Error), it is possible to test for equality in our binary search, thereby reducing the best-case number of requests to one request, with eight requests being a worst case.
This is great. We have a method by which we can efficiently extract the value of a given byte in a fixed time in as many requests as there are bits. Unless we use compression or an injection string that handles more than two states this is as good as it gets from an information theory perspective. However, there is still a performance issue with the binary search technique, since each request is dependent on the result of the previous request; we cannot make the second request before the answer to the first is known, since our second request might be to test the byte against 63 or 191. Thus, requests for a single byte cannot be run in parallel, and this violates our good sense.
Note
Although it is true that bytes could be requested in parallel, there is no good reason to stop there without attempting to parallelize bit requests. We’ll look into this further shortly.
This dependence is not intrinsic to the data, since the values of the bytes are not finalized by our requests; they remain constant in the database (constant in the sense that we are not changing them—of course, any application accessing the data could make alterations; if that is the case, all bets are off and all inference techniques become unreliable). The binary search technique grouped eight bits into a byte and inferred the value of all eight bits through eight requests. Could we not instead attempt to infer the value of a single specific bit per request (say, the second bit of the byte)? If that were possible, we could issue eight parallel requests for all bits in a byte and retrieve its value in less time than the binary search method would take to retrieve the same byte, since requests would be made side by side rather than one after the other.
Massaging bits requires sufficiently helpful mechanisms within the SQL variant supported by the database under attack. Toward that end, Table 2 lists the bit functions supported by MySQL, SQL Server, and Oracle on two integers, i and j. Because Oracle does not provide an easily accessible native OR and XOR function we can roll our own.
| Database | Bitwise AND | Bitwise OR | Bitwise XOR |
|---|---|---|---|
| MySQL | i & j | i | j | i ^ j |
| SQL Server | i & j | i | j | i ^ j |
| Oracle | BITAND(i,j) | i- | i- |
| BITAND(i,j)+j | 2*BITAND(i,j)+j |
Let’s examine a few Transact-SQL (T-SQL) predicates that return true when bit two of the first character of the username is 1, and otherwise return false. A byte that has just the second most significant bit set corresponds to hexadecimal 40 16 and decimal value 64 10, which is used in the following predicates:
ASCII(SUBSTRING(SYSTEM_USER,1,1)) & 64 = 64
ASCII(SUBSTRING(SYSTEM_USER,1,1)) & 64 > 0
ASCII(SUBSTRING(SYSTEM_USER,1,1)) | 64 >
ASCII(SUBSTRING(SYSTEM_USER,1,1))
ASCII(SUBSTRING(SYSTEM_USER,1,1)) ^ 64 <
ASCII(SUBSTRING(SYSTEM_USER,1,1))
Each of the predicates is equivalent, although they obviously have slightly different syntax. The first two use bitwise AND and are useful because they reference only the first character once, which shortens the injection string. A further advantage is that sometimes the query that produces the character could be time-inefficient or have side effects on the database, and we may not want to run it twice. The third and forth predicates use OR and XOR, respectively, but require the byte to be retrieved twice, on both sides of the operator. Their only advantage is in situations where the ampersand character is not allowed due to restrictions placed in the vulnerable application or defensive layers protecting the application. We now have a method by which we can ask the database whether a bit in a given byte is 1 or 0; if the predicate returns true the bit is 1; otherwise, the bit is 0.
Returning to the chicken counting example, the SQL that will be executed to extract the first bit of the first byte is:
SELECT COUNT(chick_id) FROM chickens WHERE status='Incubating' AND ASCII(SUBSTRING(SYSTEM_USER,1,1)) & 128=128--'
The SQL to return the second bit is:
SELECT COUNT(chick_id) FROM chickens WHERE status='Incubating' AND ASCII(SUBSTRING(SYSTEM_USER,1,1)) & 64=64--'
The SQL to return the third bit is:
SELECT COUNT(chick_id) FROM chickens WHERE status='Incubating' AND ASCII(SUBSTRING(SYSTEM_USER,1,1)) & 32=32--'
and so on, until all eight bits have been recovered. Converted into eight individual requests made to the chicken counting page we have these values for the status parameter along with the response when making the request:
status=Incubating' AND ASCII(SUBSTRING(SYSTEM_USER,1,1)) & 128=128-- (False)
status=Incubating' AND ASCII(SUBSTRING(SYSTEM_USER,1,1)) & 64=64-- (True)
status=Incubating' AND ASCII(SUBSTRING(SYSTEM_USER,1,1)) & 32=32-- (True)
status=Incubating' AND ASCII(SUBSTRING(SYSTEM_USER,1,1)) & 16=16-- (True)
status=Incubating' AND ASCII(SUBSTRING(SYSTEM_USER,1,1)) & 8=8-- (False)
status=Incubating' AND ASCII(SUBSTRING(SYSTEM_USER,1,1)) & 4=4-- (False)
status=Incubating' AND ASCII(SUBSTRING(SYSTEM_USER,1,1)) & 2=2-- (True)
status=Incubating' AND ASCII(SUBSTRING(SYSTEM_USER,1,1)) & 1=1-- (True)
Because True represents 1 and False represents 0, we have the bitstring 01110011, which is 115 10. Looking up 115 10 on an ASCII chart give us s which is the first character of the username. Our focus then shifts to the next byte and the next after that, until all bytes have been retrieved. When compared to the binary search method this bit-by-bit approach also requires eight requests, so you may wonder what the point is of all this bit manipulation; however, since each request is independent of all the others they can be trivially parallelized.
Eight requests appear to be inefficient in retrieving a single byte, but when the only available option is blind SQL injection this is a small price to pay. It goes without saying that although many SQL injection attacks can be implemented by hand, issuing eight custom requests to extract a single byte would leave most people reaching for the painkillers. Because all that differs between requests for different bits is a bunch of offsets, this task is eminently automatable, and later in this chapter we will examine a number of tools that take the pain out of crafting these inference attacks.
Tip
If you are ever in a situation where you need to have an integer value broken up into a bitstring using SQL, SQL Server 2000 and 2005 support a user-defined function, FN_REPLINTTOBITSTRING( ), which takes as its sole argument an integer and returns a 32-character string representing the bitstring. For example, FN_REPLINTTOBITSTRING(ASCII(‘s’)) returns 00000000000000000000000001110011, which is a 32-bit representation of 115 10 or s.
Alternative Channel Techniques
The second category of methods for extracting data in blind SQL injection vulnerabilities is by means of alternative channels, and what sets these methods apart from the inference techniques is that although inference techniques rely on the response sent by the vulnerable page, alternative channel techniques utilize transports apart from the page response. This includes channels such as DNS, e-mail, and HTTP requests. A further attribute of alternative channel techniques is that generally they enable you to retrieve chunks of data at a time rather than inferring the value of individual bits or bytes, which makes alternative channels a very attractive option to explore. Instead of using eight requests to retrieve a single byte, you could possibly retrieve 200 bytes with a single request. However, most alternative channel techniques require larger exploit strings than inference techniques.
